
今回はBigQueryにおけるCOUNTとCOUNT DISTINCTの違いについて。
データ分析を行う際に、データの正確なカウントは非常に重要だ。
COUNTとCOUNT DISTINCTはどちらもデータの正確なカウントに非常に便利だが、それぞれ用途や結果に大きな違いがある。
以前も私もそうだったのだが、
「COUNTとCOUNT DISTINCTって似てるけど、何が違うんだっけ?」
と違いを明確に理解出来ていない状態で使っている人も多いはずだ。
本記事ではそのような人向けにBigQuery(Google SQL)におけるCOUNTとCOUNT DISTINCTの違いにだけ焦点を当てて説明したいと思う。
目次
COUNTとCOUNT DISTINCTの違い
結論からいうと、COUNTとCOUNT DISTINCTの違いは、重複をカウントするかどうかだ。

COUNT は指定した列の全てのレコード数をカウントし、その値を返す。
例えば、下記sampleカラムには10行データがある。
この場合、COUNTは値の重複に関係なく、10という値を返す。
| sample |
| A |
| A |
| A |
| B |
| B |
| B |
| C |
| C |
| C |
| D |
1 2 3 4 5 | SELECT COUNT(sample) AS count FROM `sample_dataset.sample_table` ; |
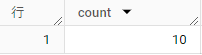
一方、COUNT DISTINCTは「重複を除いたレコード数「」=「値がユニークなレコード数」を返す。
そのため、上記データをCOUNT DISTINCTを使ってカウントすると結果は 4 となる。
なぜ4になるかというと、値の種類としてはA、B、C、Dの4つしかないからだ。
Aは全部で3行あるが、同じ値なのでCOUNT DISTINCTの場合は1と換算される。
1 2 3 4 5 | SELECT COUNT(DISTINCT sample) AS count_distinct FROM `sample_dataset.sample_table` ; |
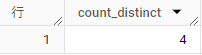
同じカラムを対象にしてCOUNTとCOUNT DISTINCTを指定してみると違いを理解しやすくなる。
1 2 3 4 5 6 | SELECT COUNT(sample) AS count ,COUNT(DISTINCT sample) AS count_distinct FROM `sample_dataset.sample_table` ; |

同じsampleカラムを対象にしているが、COUNTの場合は10。
COUNT DISTINCTの場合は4、が返されていることがお分かりいただけると思う。
NULL値がある場合
対象のカラムにNULL値がある場合は、COUNTもCOUNT DISTINCTも同じで、NULL値は無視される。
つまり、COUNTの場合は「NULL値以外の全レコード数を返す」。
一方で、COUNT DISTINCTの場合は「NULL値以外のユニークなレコード数を返す」ということだ。
例えば、下記データにおいて、sampleカラムを対象にCOUNTとCOUNT DISTINCTを実施すると下記結果となる。
| id | sample |
| 1 | A |
| 2 | A |
| 3 | A |
| 4 | B |
| 5 | B |
| 6 | B |
| 7 | C |
| 8 | C |
| 9 | null |
| 10 | null |
1 2 3 4 5 6 | SELECT COUNT(sample) AS count ,COUNT(DISTINCT sample) AS count_distinct FROM `sample_dataset.sample_table` ; |

COUNTでは値がNULLの2行が無視されて 8 が返される。
一方、COUNT DISTINCTの場合は、NULL値以外の行における値の種類(A,B,C)= 3が返されている。
このように、COUNTとCOUNT DISTINCTともに対象カラムにNULLが含まれる場合はNULL値は無視した上で計算される。
活用シーンの使い分け
活用シーンはCOUNTとCOUNT DISTINCTで大きく異なってくる。
COUNTの場合
テーブル全体のレコード数の把握
例: employeesテーブル全体のレコード数があるかを確認する。
1 2 3 4 5 | SELECT COUNT(*) FROM `sample_dataset.employees` ; |
COUNT(*)は対象テーブル(この場合はemployees)の全てのレコード数を返す指定の仕方だ。
実務ではこの COUNT(*)でテーブルのレコード数を確認するというのをよく使う。
COUNT DISTINCTではこの使い方は出来ず、COUNT(DISTINCT *)と指定すると構文エラーとなる。
特定の条件を満たすレコード数の確認
例: department=営業の条件に合致するレコード数をカウントする。
エラーが発生しました。後でもう一度やり直してください。 |
上記のように、テーブル全体ではなく「WHERE句で指定した条件に絞ったうえで該当の条件に合致するレコード数を確認したい」という時にもCOUNTは便利だ。
COUNT DISTINCTの場合
COUNT DISTINCTの場合、重複を除いたユニークな値の数を把握する際に活用される。
サイトに訪れたユニークなユーザー数をカウントする。
例:サイトのアクセス数等が記録されたweb_logテーブルにおける各月のユニークユーザー数を集計する。
1 2 3 4 5 6 7 8 9 10 | SELECT FORMAT_DATE('%Y-%m',date) AS month ,COUNT(DISTINCT user_id) AS unique_user_count FROM `sample_dataset.web_log` GROUP BY month ORDER BY month ; |
上記では、FORMAT_DATE関数とCOUNT DISTINCTを活用して、サイト分析でよく使う「各月のユニークユーザー数」を集計している。
このように、COUNT は全体のレコード数等を把握するために活用され、COUNT DISTINCT は重複を排除してユニークな値を把握するために活用される。
まとめ
今回はCOUNTとCOUNT DISTINCTの違いについて整理してみた。
要点は下記の通りだ。
- COUNTとCOUNT DISTINCTはレコード数をカウントする際に重複を含むかどうかに違いがある
- NULL値に関してはどちらも対象から除外してカウントをする
- COUNT は全体のレコード数の把握等に活用され、COUNT DISTINCT はユニークユーザー数などユニークな値を把握するために活用される
他のBigQueryの関数に関する記事は下記を参考にしてもらえると幸いだ。





