
今回はBigQueryにおけるPIVOT(ピボット)の使い方に焦点を当てて紹介する。
BigQueryの PIVOT はデータ構造を変換するためのSQL操作だ。
PIVOTや、その逆の使い方をする UNPIVOT を使えば、対象のデータをより分析しやすい形に整形することが出来るため、データ分析の幅が大きく広がる。
本記事を参考に是非PIVOTの基本的な使い方を把握して欲しい。
PIVOTとは?
PIVOT(ピボット)は指定したカラムの行データを列データに変換するものだ。
つまり、縦持ちのテーブルを横持ちのテーブルに変換してくれる。
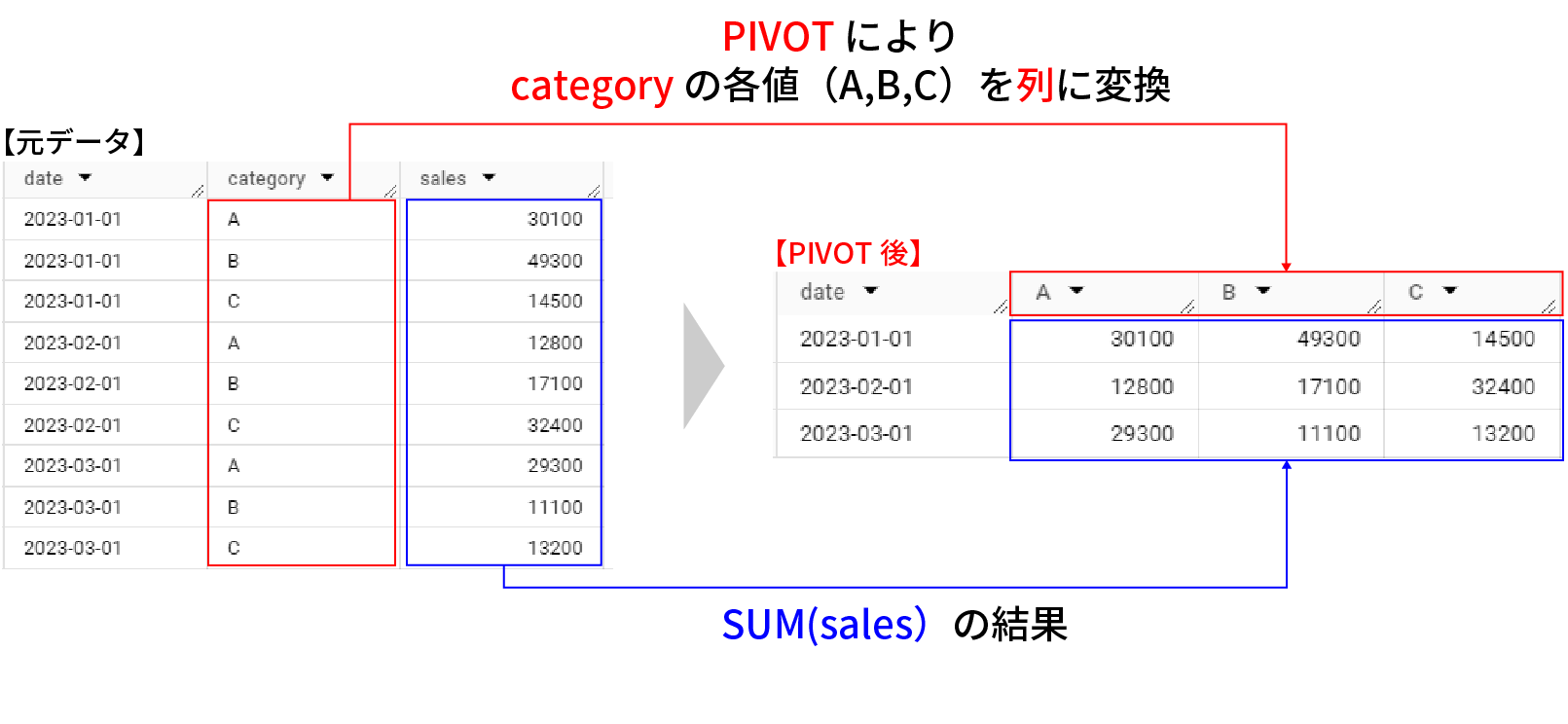
例えば、下記はPIVOTを利用することで、左側のcategoryカラムの各値を列に変換して、右側のテーブルに変換した例だ。

左側のテーブルにあるcategoryカラムのA,B,Cという値が、右側のテーブルではそれぞれカラムになっていることがお分かりいただけると思う。
PIVOT 前ではやや把握しにくかったcategoryごとの月別売上推移がぱっと見で把握出来るようになっている。
私の場合、TableauなどのBIツールでGoogle Analyticsのデータを分析をする際などに
「このカラムのこの値の範囲内かどうかでデータを絞り込みたい」
という時などにPIVOTを活用することが多い。
通常のカラム構成(上記例では左側のテーブル)では、うまく絞り込みが出来ない状態でも PIVOT を活用してデータ構造を変換すれば、意図した通りのデータに変換して分析がしやすくなる。
このように PIVOT はデータ分析がより行いやすくなるようデータの加工・整形をする際に非常に便利なものだ。
PIVOTの使い方
PIVOTの使い方はやや複雑だが、下記を指定して利用する。
- 対象のテーブル
- 集計対象カラムの指定
- 集計関数の指定(SUMやAVG等)
- 行から列に変換するカラム(ピボット対象カラム)の指定
- 列に変換する値の指定(どの値を新たな列としてピボットさせるか?)

指定する項目が多いので慣れていない内は混乱しがちだと思う。
そういう時は具体例で確認しよう。
- どの列がピボットの対象か?
- どのように変換されるか?
を確認するとグッと理解しやすくなる。
下記データを使用してPIVOTによる行から列への変換の動きを確認する。
date | category | sales |
2023-01-01 | A | 30100 |
2023-01-01 | B | 49300 |
2023-01-01 | C | 14500 |
2023-02-01 | A | 12800 |
2023-02-01 | B | 17100 |
2023-02-01 | C | 32400 |
2023-03-01 | A | 29300 |
2023-03-01 | B | 11100 |
2023-03-01 | C | 13200 |
上記データにおいて、PIVOTを利用してcategoryの各値(A,B,C)を列に変換したクエリとその指定の意味は下記の通りだ。
1 2 3 4 5 6 7 8 | SELECT * FROM `sample_dataset.sample_table` PIVOT ( SUM(sales) FOR category IN ('A', 'B', 'C') ) |
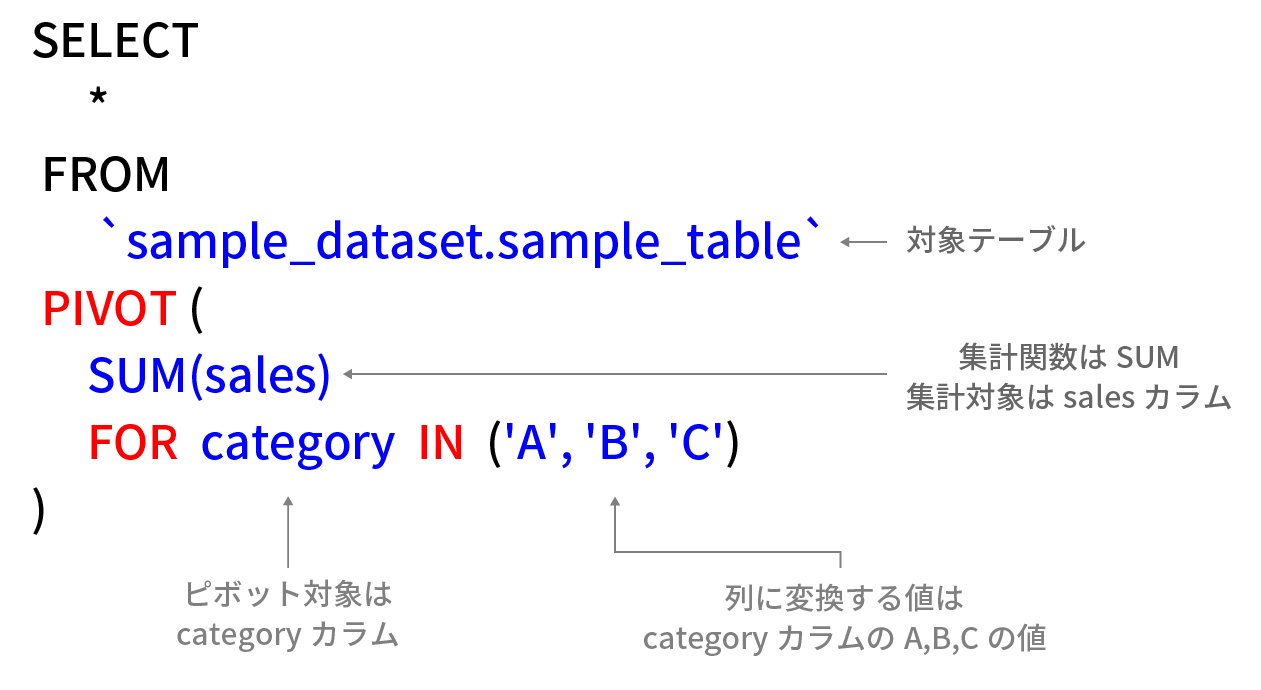
こちらのクエリの結果は下記の通りだ。
PIVOTを使用する際、集約するキー=ピボット対象カラム(行を列に変換するための基準となる値)と集約される値(実際に集約関数が適用されるデータ)を指定する必要がある。
集約キーは通常、文字列や整数など、列に変換しやすいデータ型であることが多い。
上記例の場合、集約キー=ピボットの対象となるのはcategoryカラム(STRING型)となる。
集約される値は、数値型(INT64、FLOAT、NUMERIC など)であることが一般的だ。
上記例において集約される値はsalesカラム(INT64型)で集計関数のSUMが適用されている。
列に変換する値を絞る場合
先ほどの例においてはPIVOT対象のcategoryカラムの全ての値(A,B,C)を列に変換していた。
仮に PIVOT 対象のカラムの値の内、列に変換する必要がないカラムがあれば、IN演算子の指定から外せばOKだ。
例えば、下記はcategoryカラムの値の内、AとBだけを列に変換した場合のクエリとその結果だ。
1 2 3 4 5 6 7 8 | SELECT * FROM `sample_dataset.sample_table` PIVOT ( SUM(sales) FOR category IN ('A', 'B') ) |

PIVOT 対象のcategoryカラムの値の内、IN演算子に指定したAとBのみが列に変換されたことがお分かりいただけると思う。
このように PIVOT 対象カラムの値の内、列に変換したい値だけをIN演算子に指定することで変換後の列を絞り込むことが可能だ。
PIVOT対象テーブルをサブクエリにする場合
PIVOTの対象テーブルを直接テーブル名で指定するのではなく、サブクエリにすることも可能だ
PIVOTする際に対象のテーブルの内、使いたい列が限られている場合がよくある。
そういう場合にサブクエリを対象とするのだ。
先ほどと同様のデータを使って、サブクエリを対象とするPIVOTの挙動を確認していこう。
date | category | sales |
2023-01-01 | A | 30100 |
2023-01-01 | B | 49300 |
2023-01-01 | C | 14500 |
2023-02-01 | A | 12800 |
2023-02-01 | B | 17100 |
2023-02-01 | C | 32400 |
2023-03-01 | A | 29300 |
2023-03-01 | B | 11100 |
2023-03-01 | C | 13200 |
上記データにおいて、dateカラムを除外してから、先ほどと同様にcategoryカラムにPIVOTを適用する場合のクエリは下記の通りだ。
1 2 3 4 5 6 7 8 9 10 11 12 | SELECT * FROM (SELECT category ,sales FROM `sample_dateaset.sample_table`) PIVOT ( SUM(sales) FOR category IN ('A', 'B', 'C') ) |
上記クエリを実施した結果は下記となる。

サブクエリでdateカラムが除外されたことにより、元々9行あったデータが1行に集約されていることがお分かりいただけると思う。
上記クエリの実際の流れは下記のイメージだ。
- 元データ(date,category,salesの3カラム)
- サブクエリ実行後(category,salesの2カラム)
- PIVOT実行後(categoryの各値=A,B,Cの3カラム)
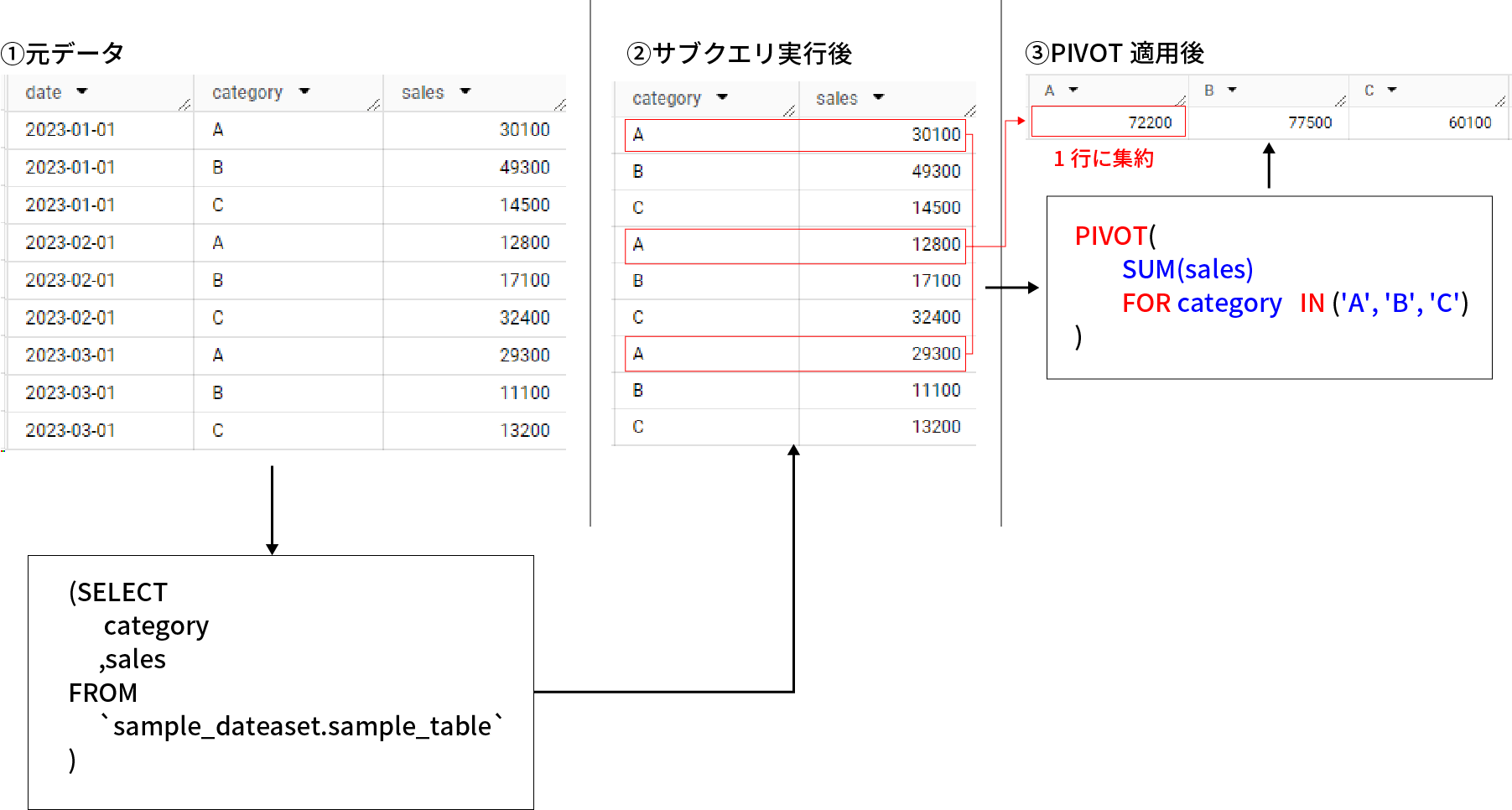
上記例の場合、元々salesの各値を分けていたdateカラムとcategoryカラムがサブクエリとPIVOTにより、結果カラムから消えている。
そのため、salesの各値はPIVOT適用時に指定していたSUM(sales)により、Aの売上の合計値、Bの売上の合計値、Cの売上の合計値、という形で1行に集約されている。
集計関数を変更した場合の挙動
PIVOT適用時の集計関数をSUMではなく、MAXに変更した場合のクエリとその結果は下記となる。
1 2 3 4 5 6 7 8 9 10 11 12 | SELECT * FROM (SELECT category ,sales FROM `sample_dateaset.sample_table`) PIVOT ( MAX(sales) FOR category IN ('A', 'B', 'C') ) |
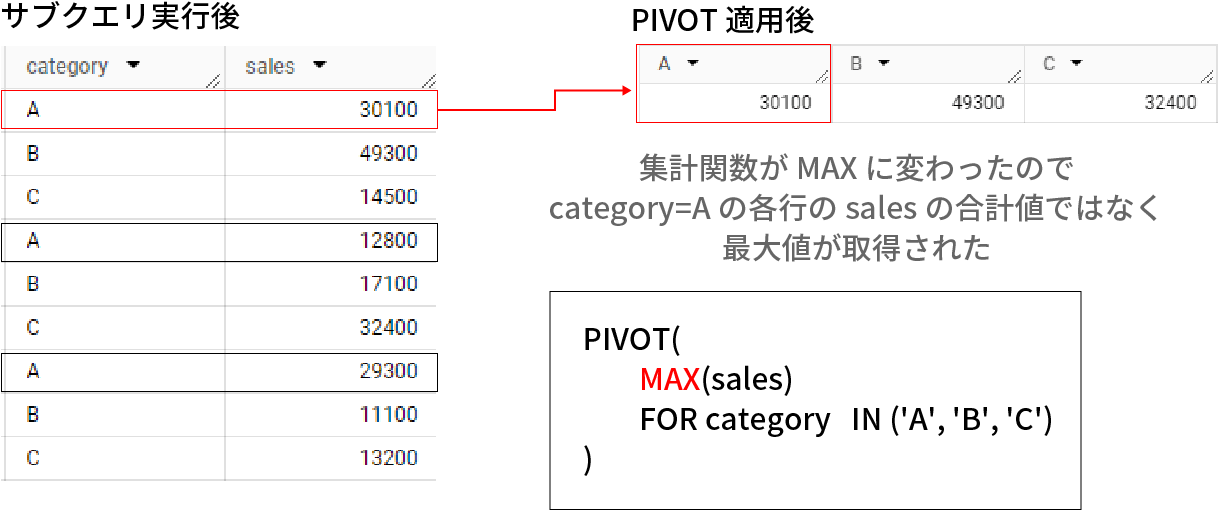
PIVOT適用後のA,B,Cのカラム値が先ほどの例と変わったことがお分かりいただけると思う。
先ほどの例ではPIVOTの集計関数において合計を取得するSUM(sales)を指定していたが、上記例では最大値を取得するMAX(sales)を指定している。
これにより、PIVOT適用後の結果はcategory=Aの各行におけるsalesの最大値が取得されているのだ。
このように、元データから不要なカラムをサブクエリで除外するなどして、レコードが集約される場合は集計関数に何を選ぶかによってPIVOT後の値が変わってくる。
まとめ
本記事で紹介したBigQueryにおけるPIVOTの要点は下記の通りだ。
- PIVOT(ピボット)は指定したカラムの行データを列データに変換するSQL操作
- PIVOTはデータ分析の幅を広げる大きな武器となる
- PIVOTで行から列に変換するカラムは絞りこむことが可能(IN演算子の指定から外せばOK)
- 集計関数に何を選択するかによってPIVOT後のレコード集約時に表示される値が変わる
- PIVOTの対象にサブクエリで作成した一時テーブルを指定することも可能
BigQueryに関する他の記事に関しては下記で紹介しているので是非参考にして欲しい。





