Tableauの文字列関数の使い方をまとめてご紹介したいと思う。
紹介する文字列関数はTableauコンサルタントとして私が実務で使ってきた関数や今後使う可能性がありそうなものに絞っているが、本記事で紹介する文字列関数を使いこなせればTableauで出来ることは飛躍的に増えるはずだ。
一気に覚えるのは難しいので使用頻度別(あくまで私の個人的な経験上の基準)に関数を分けてみた。
まずは使用頻度が高い関数から覚えてみてもらえれば幸いだ。
使用頻度:高
まずは実務で使用頻度が高い文字列関数から紹介していく。
CONTAINS関数
CONTAINS関数は対象の文字列のデータに特定の文字列が含まれているかを判定してくれる関数だ。
例えば、下記はIF文とCONTAINS関数を組み合わせて、製品名の中に「はさみ」が含まれている場合は「はさみ」と表示し、含まれていない場合は「その他」と表示させている例だ。
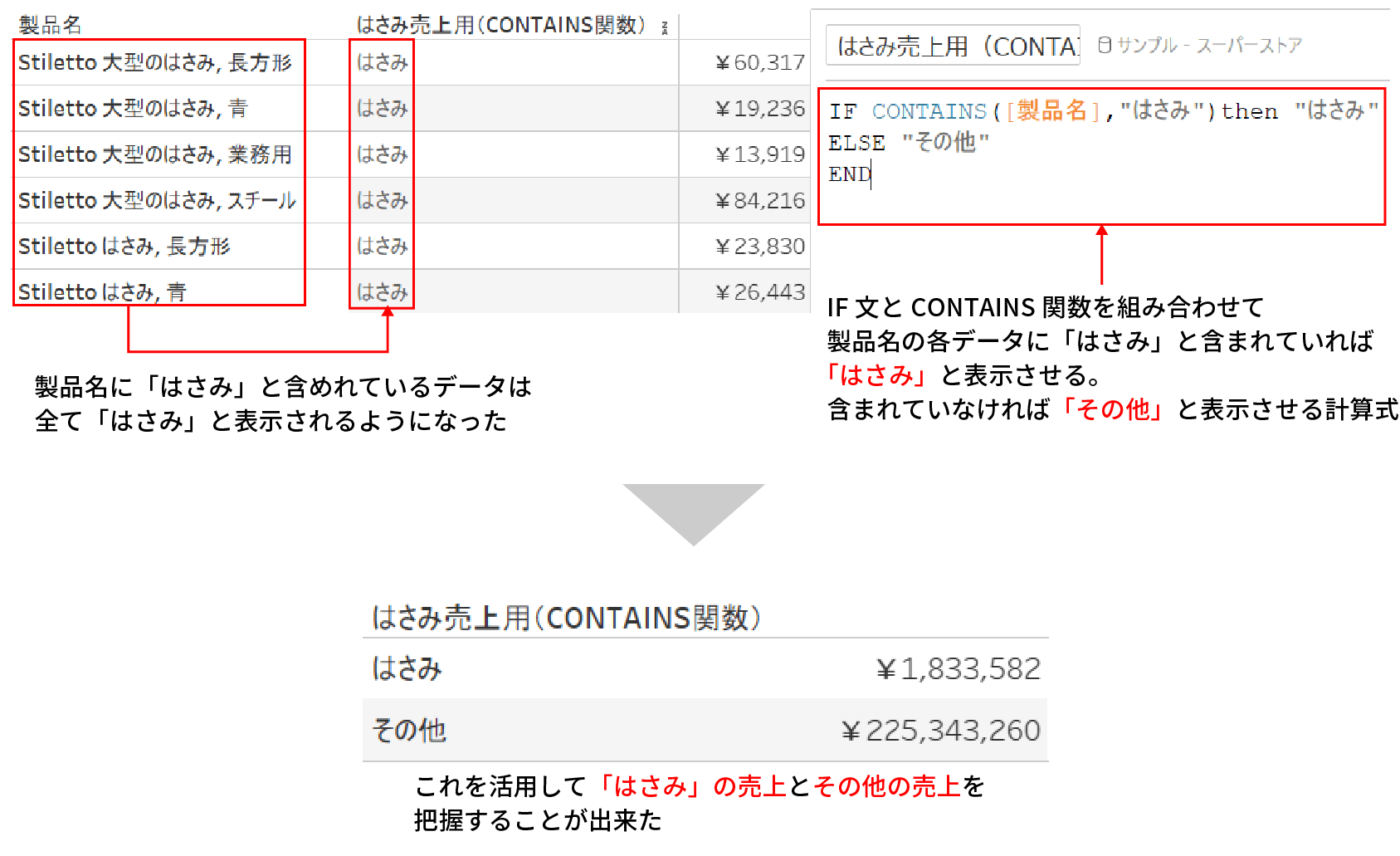
製品名の各値において「はさみ」という文字列が含まれている製品とそうでない製品で売上を区分けすることが出来るようになったのがお分かりいただけると思う。
CONTAINS関数の使い方
CONTAINS関数の使い方は下記の通りだ。
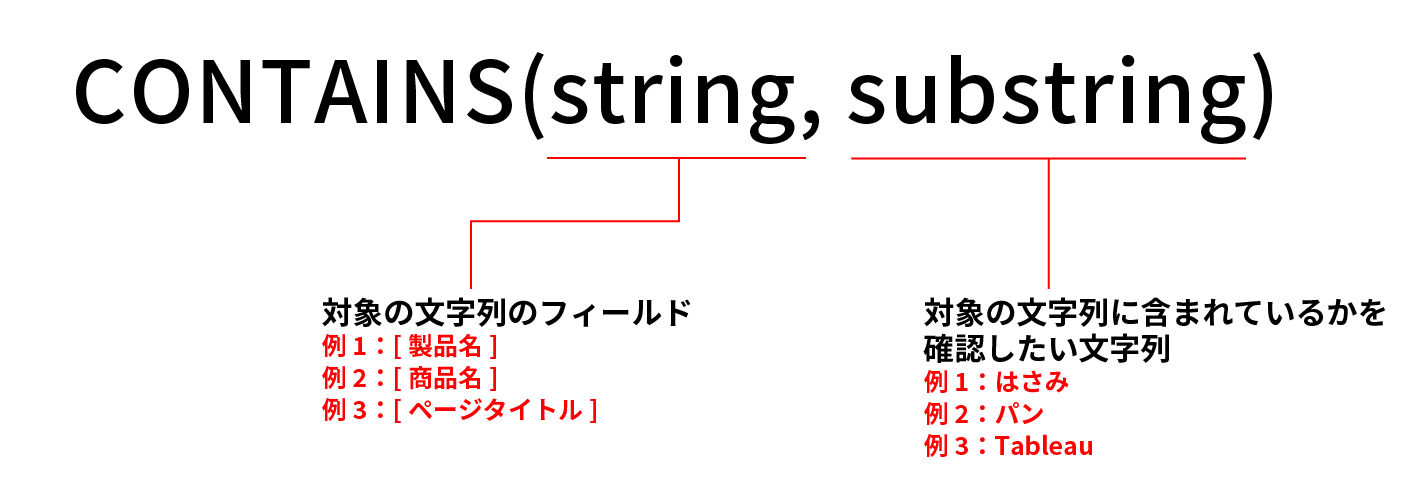
具体的な計算フィールドに当てはめると下記の意味になる。
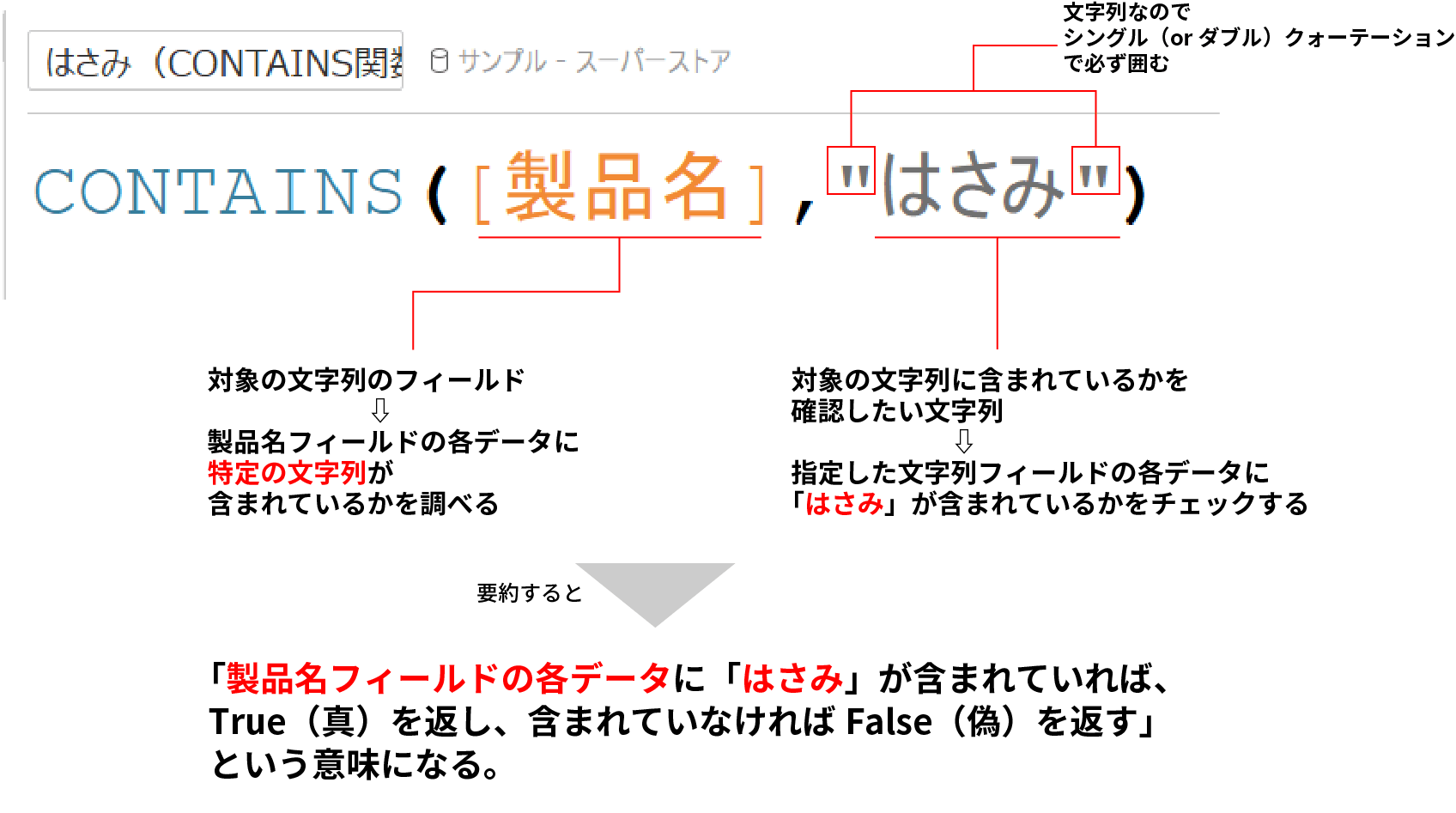
慣れていない頃は指定した文字列を’シングルクォーテーションやダブルクォーテーションで囲むのを忘れがちなので、要注意だ。
個人的にCONTAINS関数は文字列関数の中で最もよく使う関数だ。
IF文と組み合わせて使うことが多く、除外用のフラグを作成したり、Google Analytics分析の際にURLの中で特定の文字列が含まれているページだけを集計する、などでよく使う。
CONTAINS関数の詳細は下記記事にまとめているので、詳しく知りたい方は参考にして欲しい。
【Tableau】CONTAINS関数とは?意味から使い方までわかりやすく解説
LEFT関数
LEFT関数は対象の文字列の一番左から指定した文字数までの文字を返してくれる関数だ。
例えば、会員番号が下記のような場合に
「一番左のアルファベットを取り出してフィルターとして使用したい」
という時などにLEFT関数は活躍してくれる。
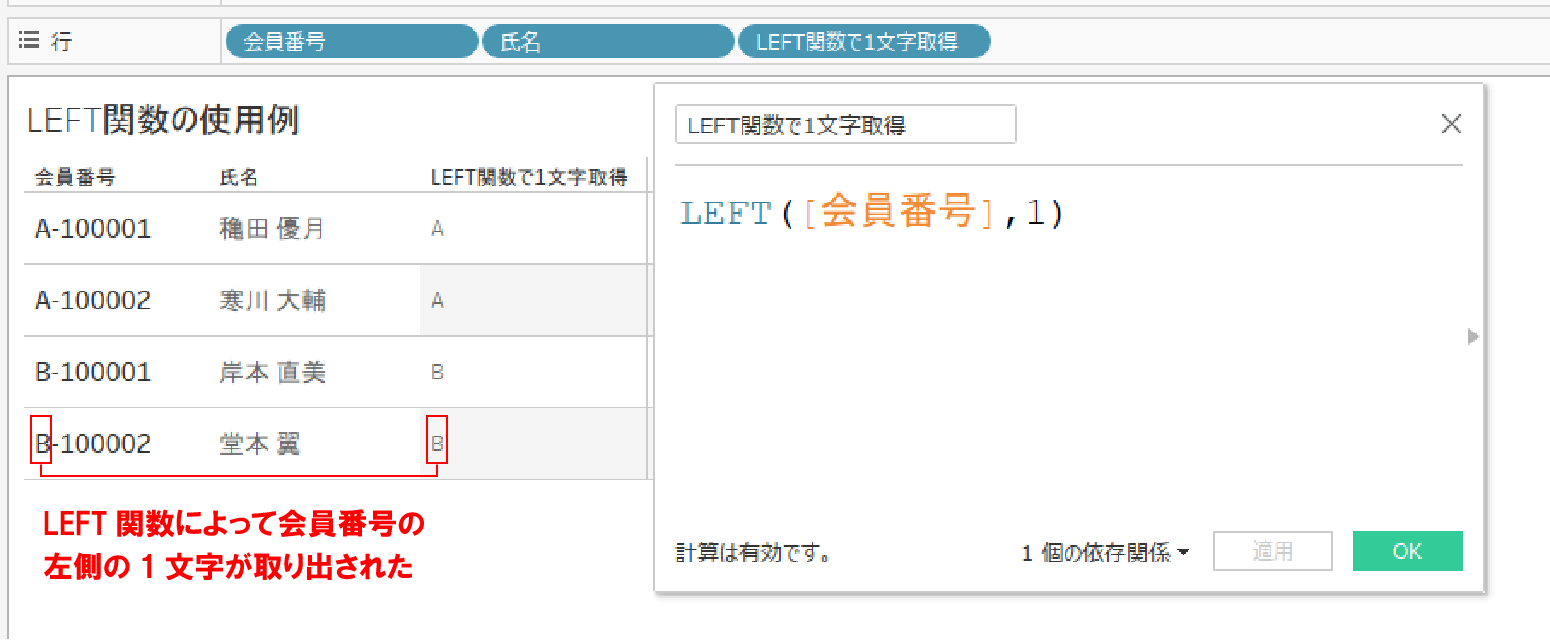
会員番号や取引先IDの先頭に顧客カテゴリや取引先の分類コードが含まれていることはよくあり、LEFT関数を使う機会は比較的よくあるはずだ。
LEFT関数の使い方
LEFT関数の使い方は非常にシンプルで、ExcelのLEFT関数の使い方ともほぼ同じなので覚えやすい。
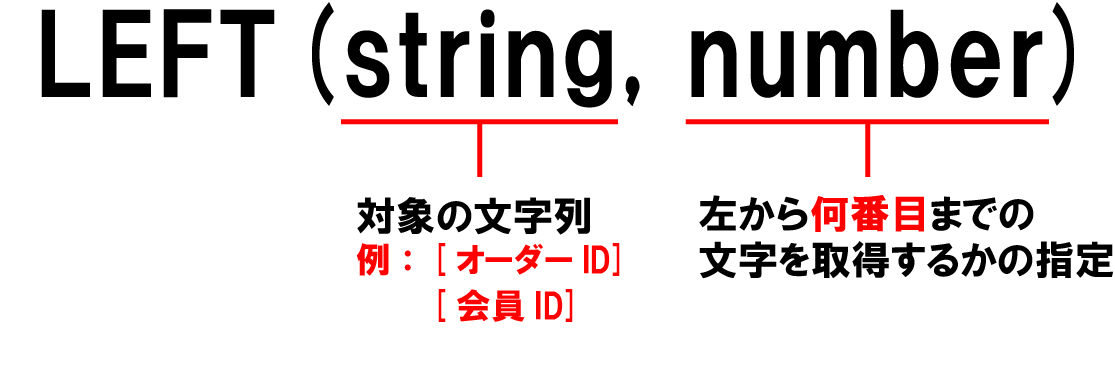
先ほどの例に当てはめると下記のようになる。

LEFT関数を使用する時の注意点
LEFT関数はその名の通り、左側から指定した文字数を取得してくれるので、逆に右側から~文字を取得したいという場合は使えない。
そういう時は後述するRIGHT関数やMID関数を利用すると良いと思う。
また、取り出したい文字数が値によって異なる場合もLEFT関数単独では使いづらい。
FIND関数やLEN関数を組み合わせれば、意図通りに文字列を取得できる場合もあるが、その場合は次に紹介するSPLIT関数等を利用した方がよっぽど簡単な場合が多い。
LEFT関数の詳細は下記記事にまとめているので、詳しく知りたい方は参考にして欲しい。
【Tableau】LEFT関数とは?使い方やSPILIT関数との違いまでわかりやすく解説!
SPLIT関数
SPLIT関数は対象の文字列を区切り文字(ハイフンとかカンマとか)で分割し、分割後の文字列を取得してくれる関数だ。
例えば、SPLIT関数を使い、サンプルスーパーストアのオーダーIDを - (ハイフン)で分割して先頭の2文字を取得した例が下記だ。
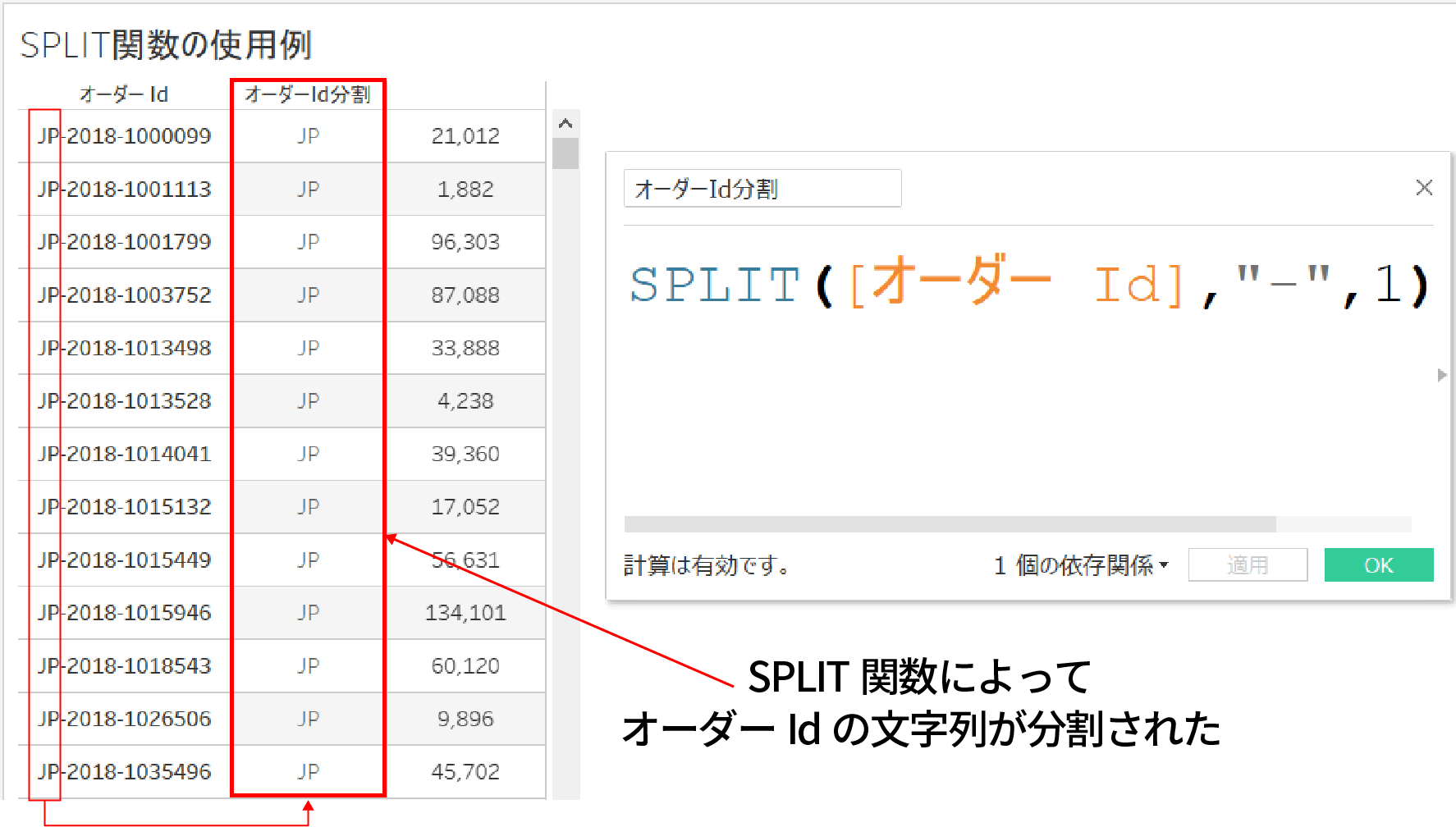
SPLIT関数の場合、LEFT関数等と異なり、取得する文字数は指定しない。
単純に指定した区切り文字により分割された文字列を取得してくれるので、文字数が一定でないデータに関しても使えるのが便利な点だ。
SPLIT関数の使い方
SPLIT関数の使い方は下記だ。

区切り文字は記号ではなく、数字や漢字など何でも指定可能だ(指定した経験は今までない(笑))。
先ほどの例に当てはめると下記のようになる。
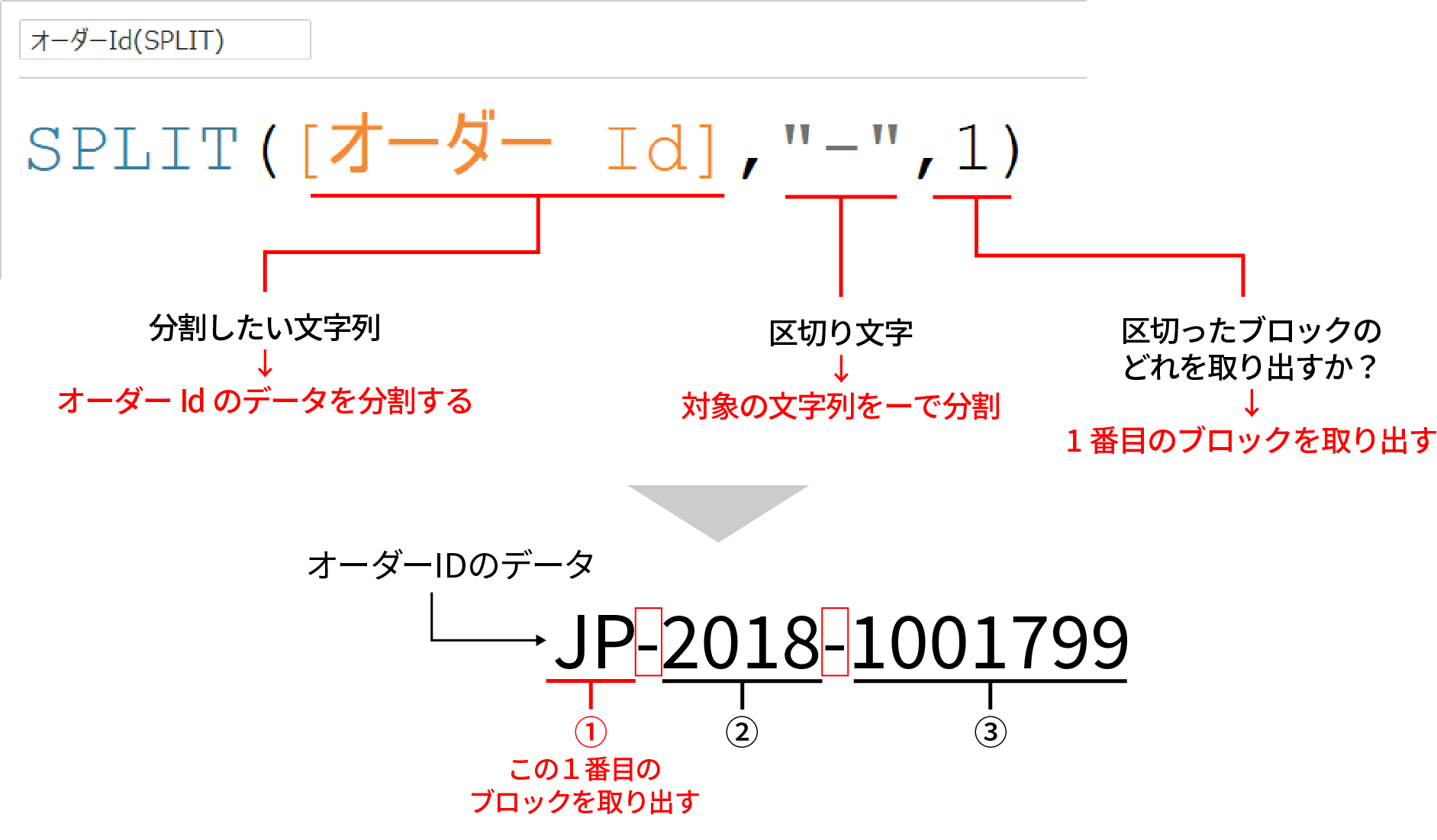
上記例では区切ったブロックの1番目を取り出しているが、2番目や3番目を指定することも出来る。
- 1番目を指定した場合の値:JP
- 2番目を指定した場合の値:2018
- 3番目を指定した場合の値:1001799
上記例をみてお分かりになる通り、指定した区切り文字はあくまで区切りの基準で使われるだけで、取得される文字列には含まれない点は覚えておきたい。
SPLIT関数の詳細は下記記事にまとめているので、詳しく知りたい方は参考にして欲しい。
【Tableau】SPLIT関数とは?意味から使い方までわかりやすく解説!
使用頻度:中
次に使用頻度が中程度の文字列関数に入っていく。
FIND関数
FIND関数とは指定した文字列が、対象の文字列の何番目に出現するかの位置を返してくれる関数だ。
例えば、サンプルスーパーストアの製品Idフィールドの各文字列に含まれている -(ハイフン)の位置をFIND関数で取得すると下記のようになる。
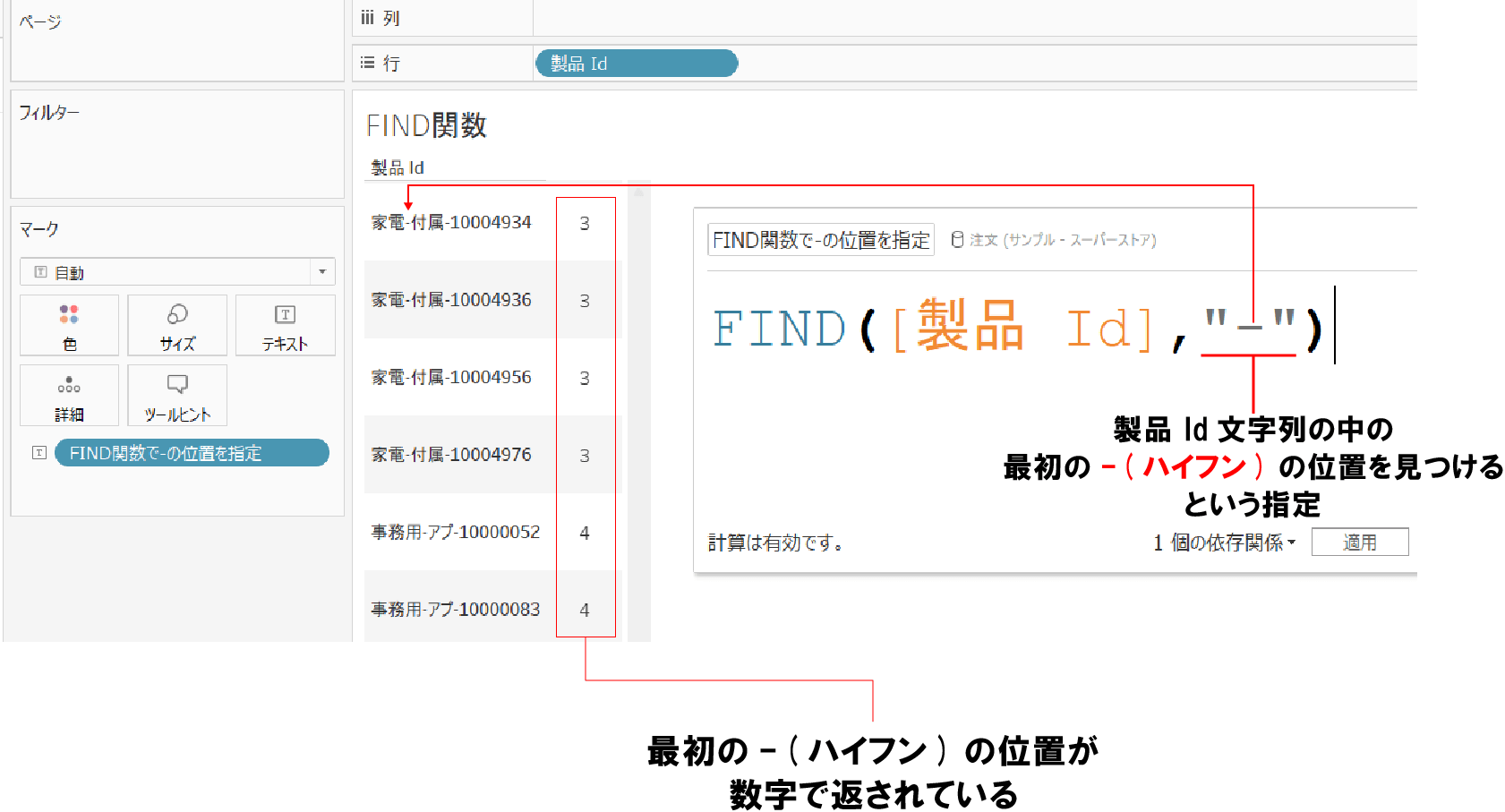
上記のようにFIND関数は対象の文字列に含まれている特定の文字列の位置を整数で返してくれる。
そのため、指定した文字数を取得できるLEFT関数やMID関数などの他の文字列関数と組み合わせて使うことが多く、単独で使うことはほとんど無いと思われる。
FIND関数の使い方
FIND関数の使用方法は下記の通りだ。
開始位置を指定する[start]に関して、オプションなので省略可能である。

先ほどの例に当てはめてみると下記のようになる。
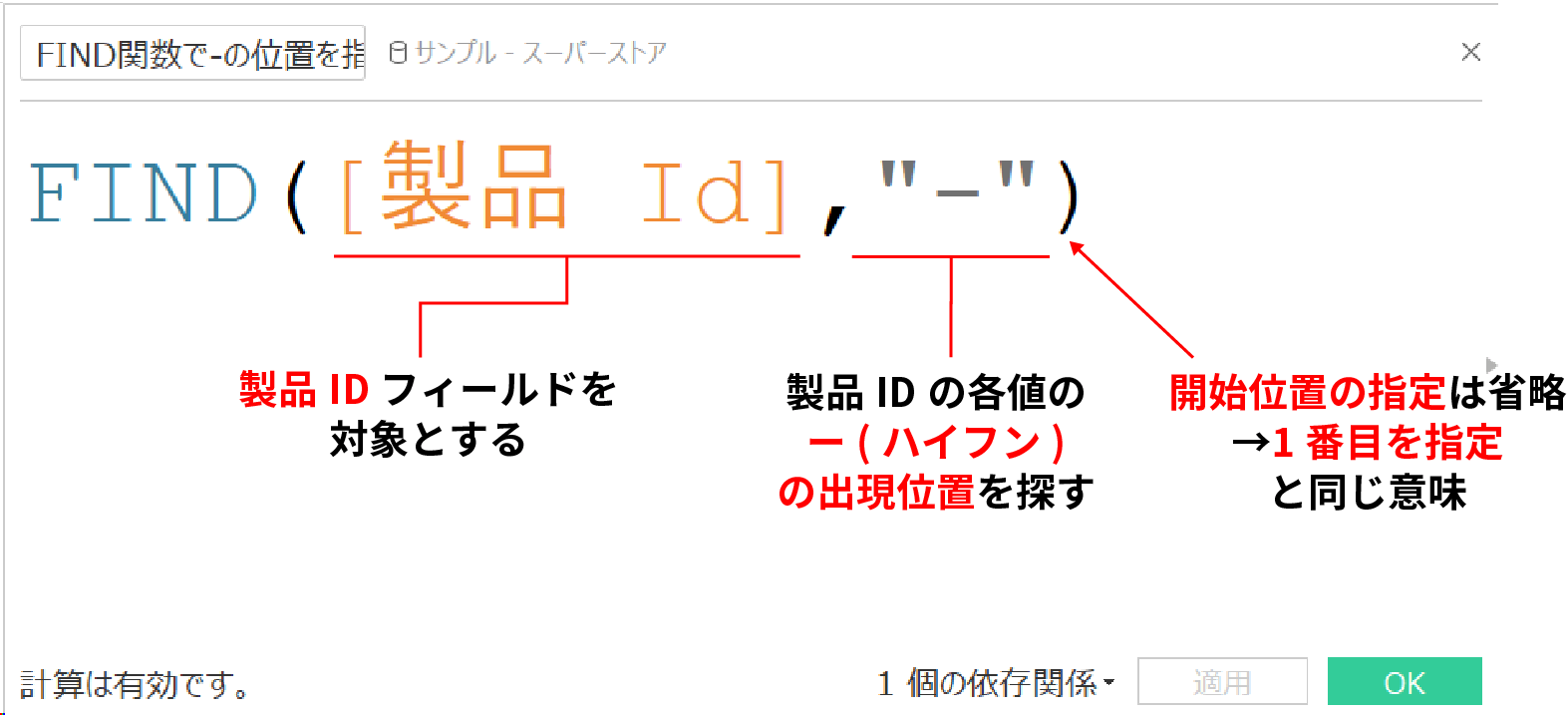
上記例の場合は開始位置は省略している。
FIND関数は指定した文字列(上記例だとハイフンなど)が最初に出現した位置を整数として返してくれる。
開始位置を指定するのは、
「最初のハイフンを除いた2番目のハイフンの出現位置を取得したい」
という場合などが該当するかと思うが、その場合は後述するFINDNTH関数を使う方が楽かもしれない。
FIND関数の詳細は下記記事にまとめているので、詳しく知りたい方は参考にして欲しい。
【Tableau】FIND関数とは?意味から使い方までわかりやすく解説!
FINDNTH関数
FINDNTH関数は指定した文字列を出現頻度(2回目に出現した場合等)まで指定した上で、対象の文字列の中での出現位置を返してくれる関数だ。
FIND関数に似ているが、FIND関数は「指定した文字列が最初に出現する位置を返す」のに対し、FINDNTH関数は「2回目に出現した時の位置や3回目に出現した位置を返す」等の細かい指定が可能だ。
例えば、下記はFINDNTH関数を使用して、オーダーIdの各値において -(ハイフン)が1回目に出現する場合と2回目に出現する場合のそれぞれの位置を取得している例だ。

FINDNTH関数で指定した出現頻度によって取得する値が異なることがお分かりいただけると思う。
FINDNTH関数の使い方
FINDNTH関数の使い方はFIND関数とよく似ているが、そこに出現頻度の指定が加わる。

先ほどの例に当てはめると下記のようになる。
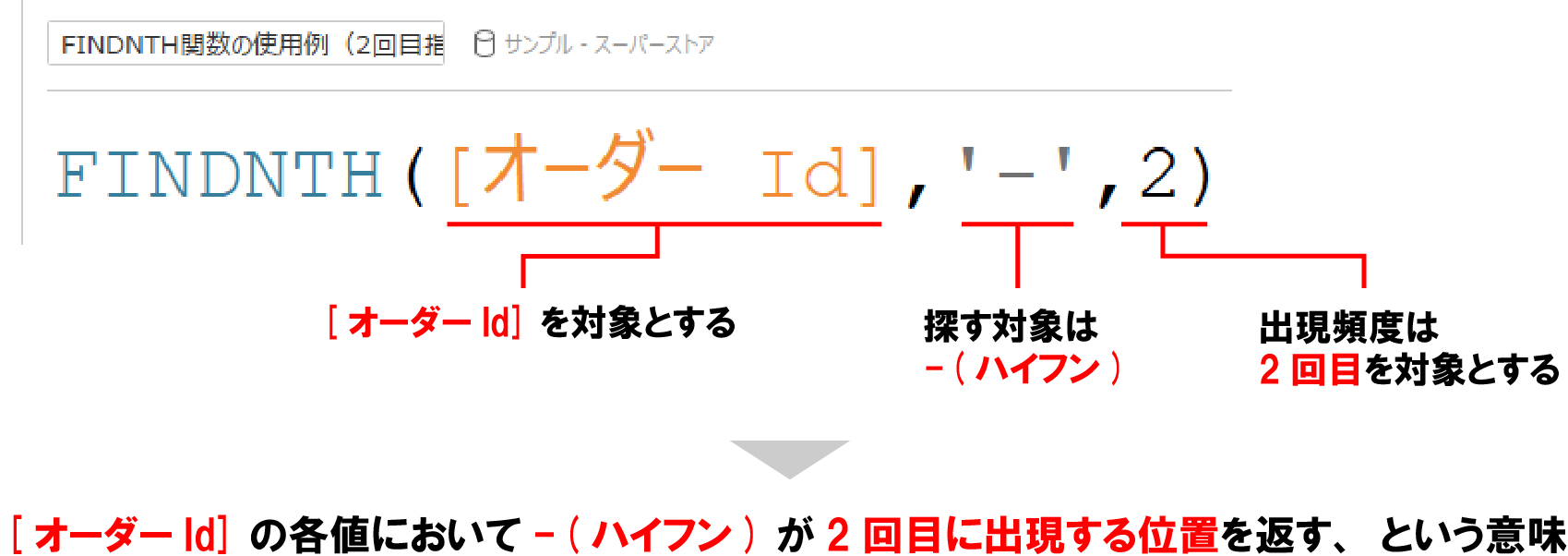
このようにFINDNTH関数は対象文字列において、指定した文字列が~回目に出現する位置を取得することが出来る便利な関数だ。
FINDNTH関数が返す値はFIND関数と同様に整数なので、LEFT関数やSPLIT関数と組み合わせることでかなり柔軟に文字列操作を行うことが出来る。
逆に単独で使う機会はFIND関数と同様にほぼ無いだろう。
LEN関数
LEN関数は対象の文字列の文字数を返してくれる関数だ。
例えば、下記は顧客の名字の文字数をLEN関数で取得している例だ。
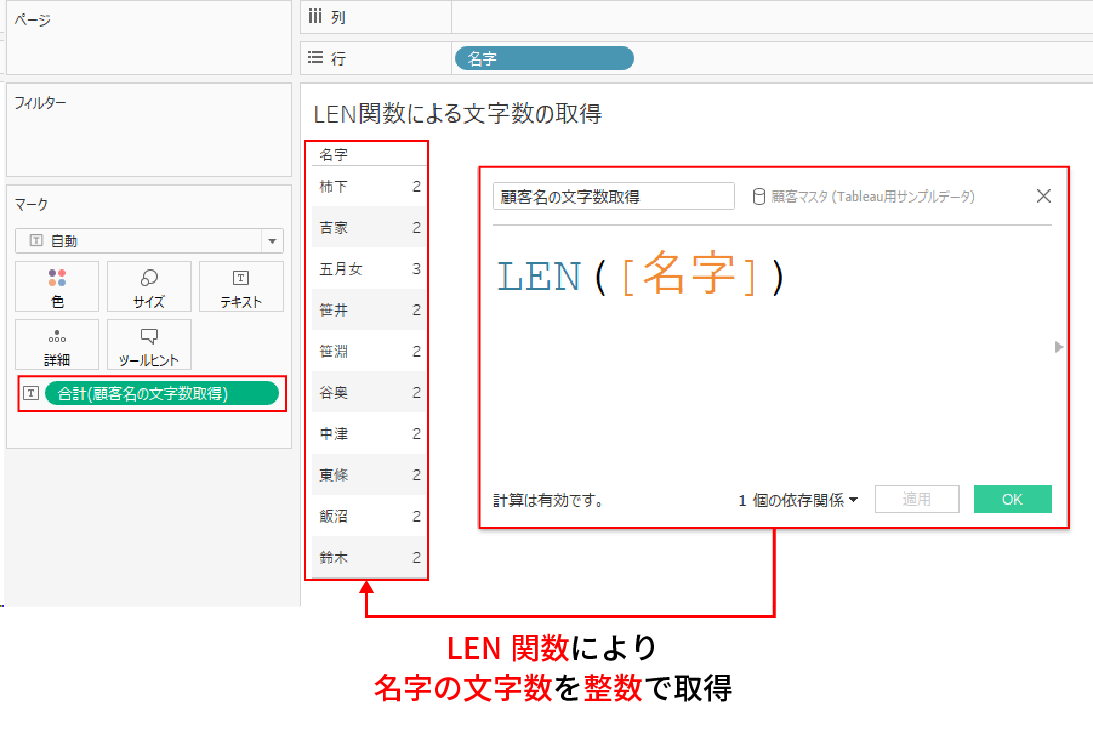
名字の文字数によって、LEN関数が返す値が変わっているのがお分かりいただけると思う。
LEN関数の注意点としては半角スペースや全角スペースも1文字として数えるので、その点は注意点として覚えておきたい。
LEN関数の使い方
LEN関数の使い方は他の文字列関数に比べるとすごくシンプルだ。
文字数を取得した対象の文字列を指定するだけでOK。

LEN関数は非常にシンプルで簡単に使えるが、単独で使う機会はほぼ無いと思う。
LEN関数が返す値は「整数」という性質を利用してLEFT関数やMID関数の文字数の指定部分で活用するという使い方が考えられるだろう。
MID関数
MID関数とは対象の文字列の指定した位置からn文字分取得してくれる関数だ。
例えば、下記はMID関数を利用して、オーダーIDの各値の真ん中あたりに位置しているオーダー年数を取得している例だ。
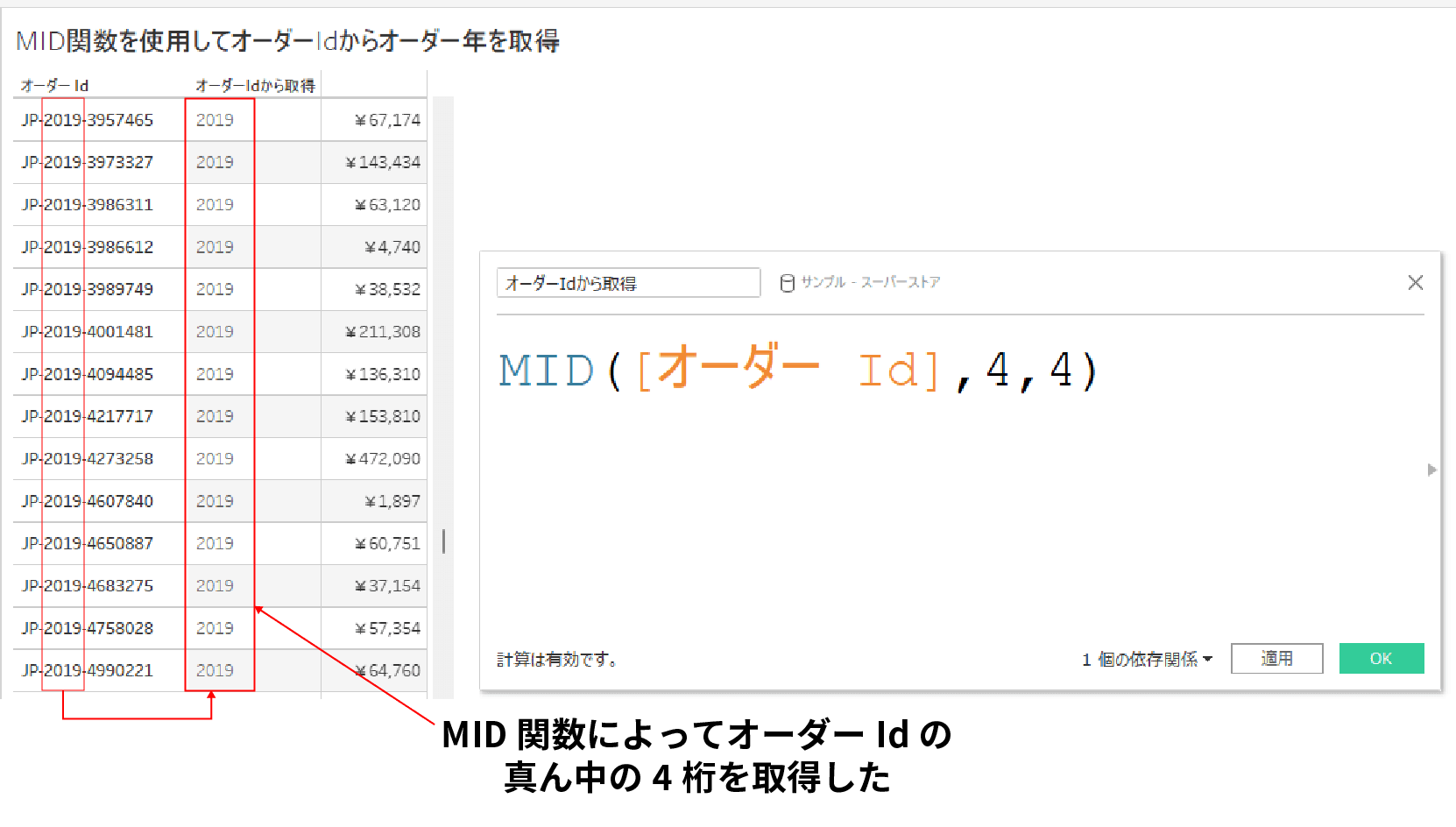
このようにMID関数は文字数が決まっている文字列データにおいて
「この真ん中の~文字分を取り出したい!」
という時に便利な関数だ。
MID関数の使い方
MID関数の使い方は下記の通りだ。

最後の[length]部分(何文字を切り取るかの指定)は省略可能だ。
省略した場合は「開始位置から最後までの文字を取得する」という意味になる。
先ほどの例に当てはめると下記のように指定している。

上記例の場合はSPLIT関数でも-(ハイフン)を区切り文字にすれば同じ結果を取得できるが、MID関数の場合は文字数が決まっていれば、特定の区切り文字がなくても活用できる点がメリットだ。
逆に文字数がバラバラな場合はLEFT関数と同様にMID関数は使用しにくいので、その場合はSPLIT関数等を利用すると良いだろう。
MID関数についてもっと詳しく知りたい方は下記記事を参考にして欲しい。
【Tableau】MID関数とは?意味や使い方までわかりやすく解説!
REPLACE関数
REPLACE関数は対象の文字列において、置き換えたい文字列を指定した別の文字列に置換してくれる関数だ。
例えば、下記は郵便番号フィールドの各データにあるー(ハイフン)をREPLACE関数で置き換えた例だ
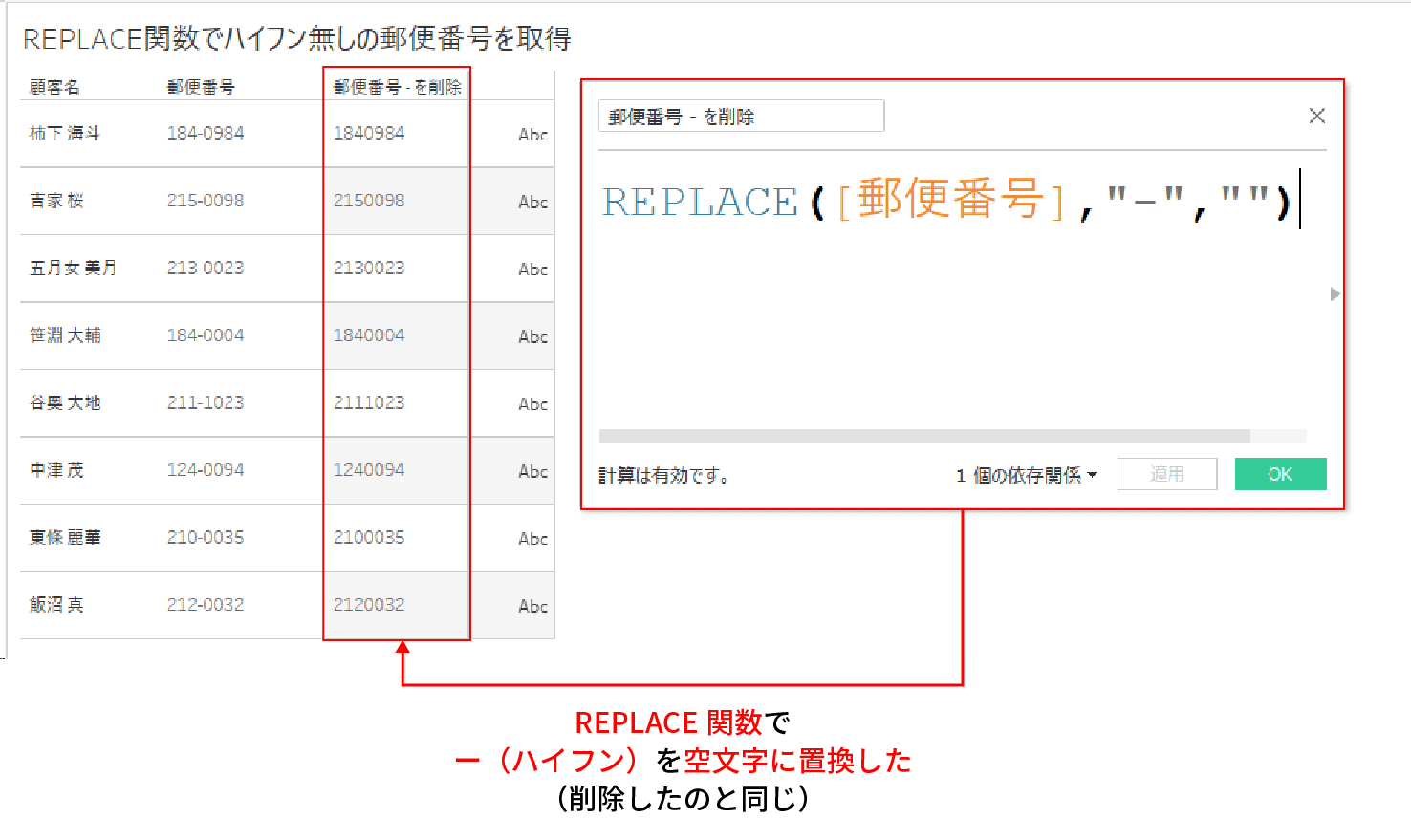
郵便番号に含まれていた - (ハイフン)が削除されているのがお分かりいただけると思う。
このようにREPLACE関数は特定の文字を別の文字に置換したり、文字列に含まれている余分な記号を削除したりする時に便利な関数だ。
REPLACE関数の使い方
REPLACE関数の使い方は下記の通りだ。
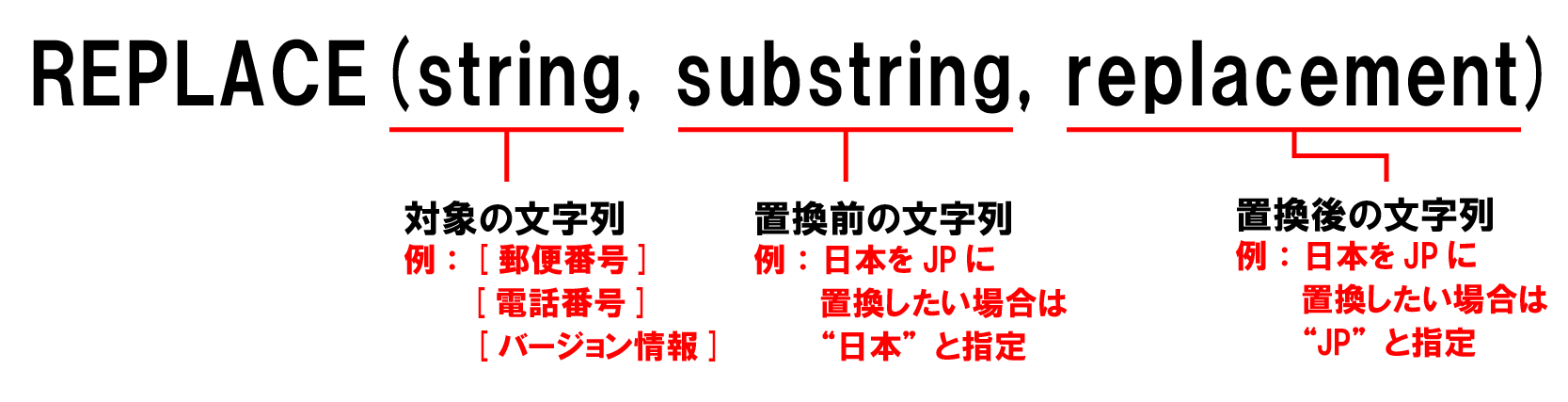
対象の文字列の中で置換したい文字列を指定し、それをどの文字列と置換するかを指定する。
先ほどの例に当てはめると下記のようになる。
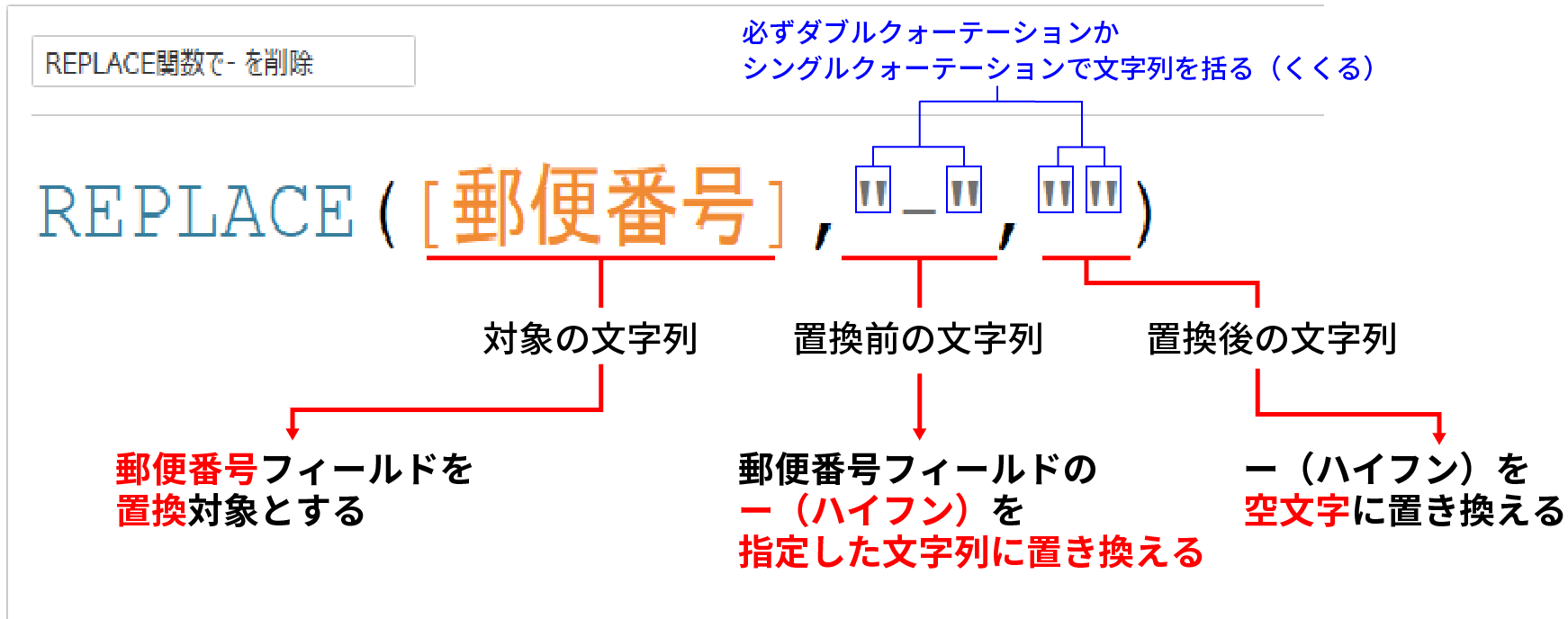
特定の文字列を削除したい場合は、置換後の文字列に何も指定しないでただシングルクォーテーションもしくはダブルクォーテーションで囲むようにすればOKだ。
上記例でも - (ハイフン)を削除したいので、置換後の文字列は""と何も指定せず、ただダブルクォーテーションで囲んでいる。
私個人的には、- (ハイフン)や文字列の中に含まれている余分な空白を除外する時にこのREPLACE関数を使うことが多く、知っておくと結構便利な関数だ。
REPLACE関数についてもっと詳しく知りたい方は下記記事を参考にして欲しい。
【Tableau】REPLACE関数とは?意味や使い方までわかりやすく解説!
TRIM関数
TRIM関数は文字列の先頭と末尾の空白を削除してくれる関数だ。
例えば、下記のように先頭にスペースが入ってしまっている顧客名フィールドにTRIM関数を適用した例だ。
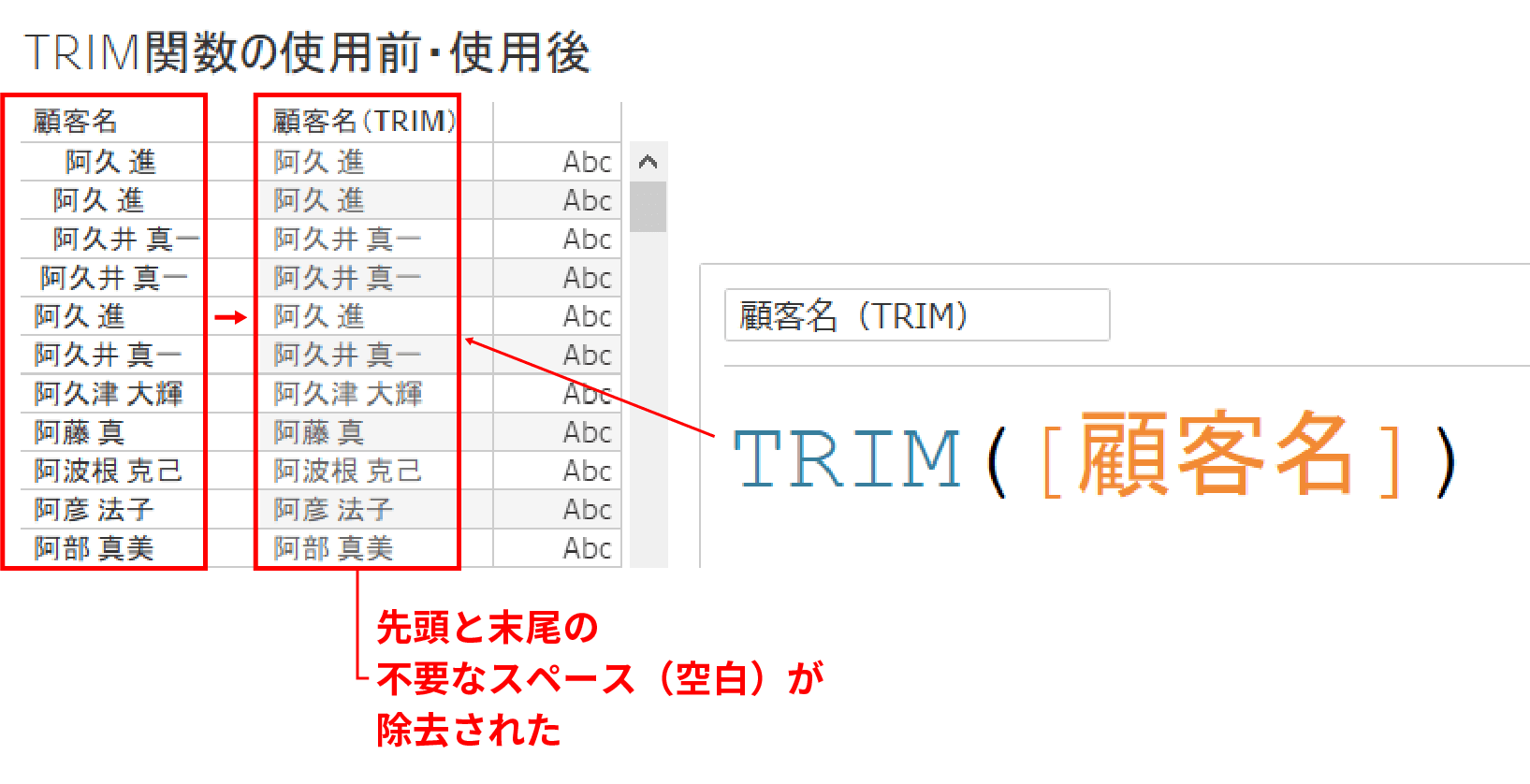
末尾の空白削除は分かりにくいと思うが、先頭の空白が削除されていることがお分かりいただけると思う。
このようにTRIM関数は「不要なスペースのせいでデータが分かれてしまっている、、、」という時に便利な関数だ。
TRIM関数の使い方
TRIM関数の使い方は下記の通りだ。
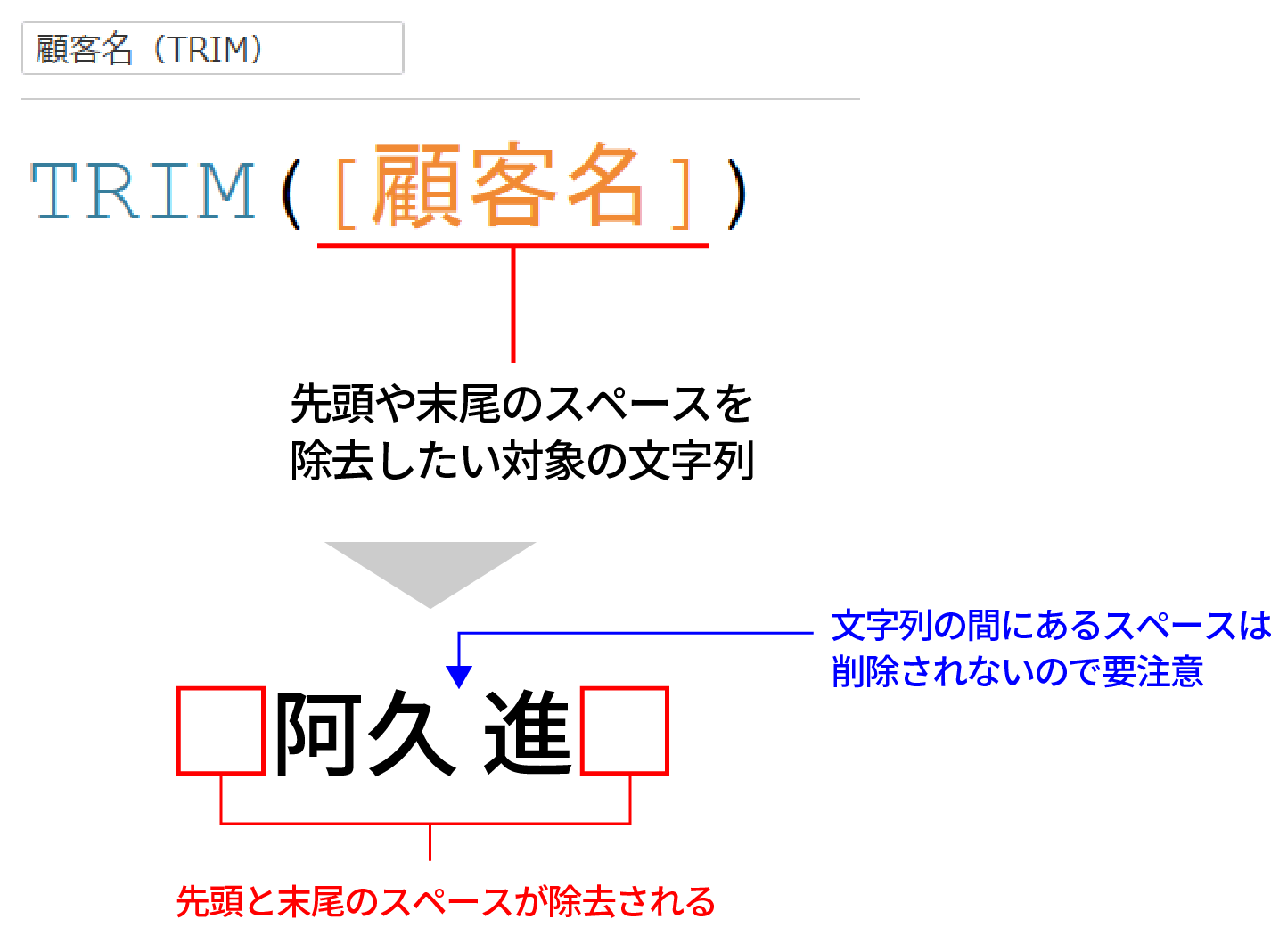
先頭と末尾のスペースを削除したいフィールドを指定するのみで使うことが出来る。
ただし、上図にも記載の通り、文字列の間にあるスペースは削除されないのが難点なので、その場合は前述したREPLACE関数等を使用して空白を削除する。
もしくはSPLIT関数で名字と名前を分割したうえでTRIM関数を使い、その後にそれぞれの文字列を結合する、などの方法が有効だと思う(Tableau Prepなら一発で全ての空白を削除することが出来る)。
TRIM関数についてもっと詳しく知りたい方は下記記事を参考にして欲しい。
【Tableau】TRIM関数とは?意味からLTRIM・RTRIM関数との違いまで分かりやすく解説!
使用頻度:低
ENDSWITH関数
ENDSWITH関数は対象の文字列の中で指定した文字列が末尾に含まれているかを判定して、TRUEもしくはFALSEを返してくれる関数だ。
例えば、下記は顧客Idの最後の文字が5かどうかをENDSWITH関数を使用して判定している例だ。
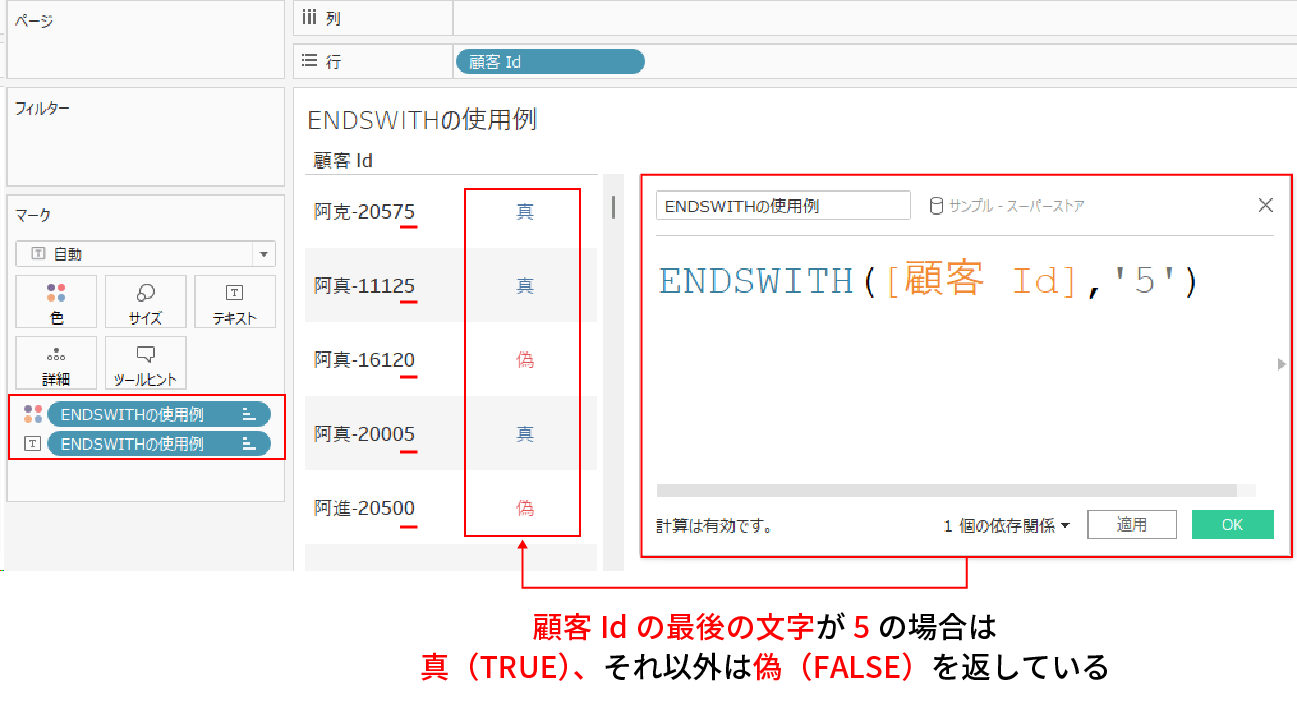
顧客Idの最後の文字が5の場合は真(TRUE)、それ以外は偽(FALSE)の値が返されていることがお分かりいただけると思う。
ENDSWITH関数の使い方
ENDSWITH関数の使い方は下記の通りだ。
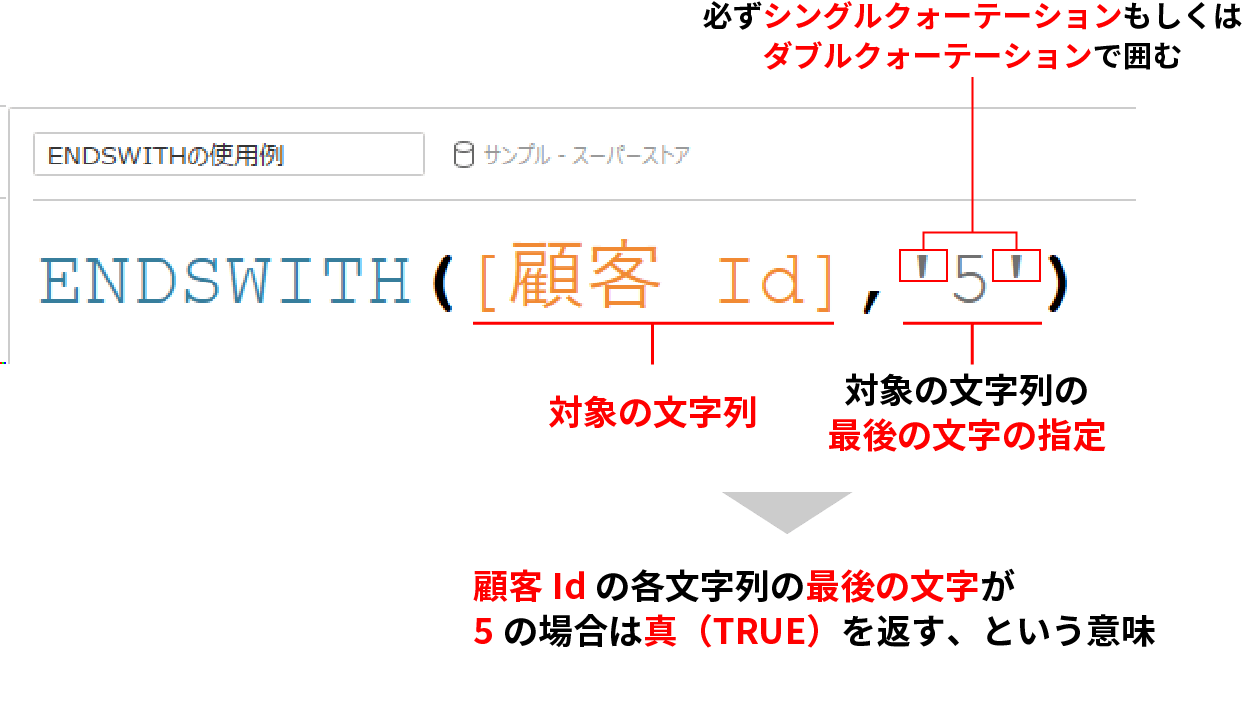
上図では最後の文字と記載しているが、1文字ではなく、例えば、.pdf で終わる文字列を判定するという場合にも利用可能だ。
特定の拡張子で終わるファイルや特定の文字列で終わる製品を判定してデータのフィルタリングをしたい場合などにENDSWITH関数を活用できると思う。
LOWER関数
LOWER関数とは対象の文字列の全ての文字を小文字に変換してくれる関数だ。
例えば、下記ではLOWER関数を使用して、大文字と小文字が混じっている値を全て小文字に変換している。
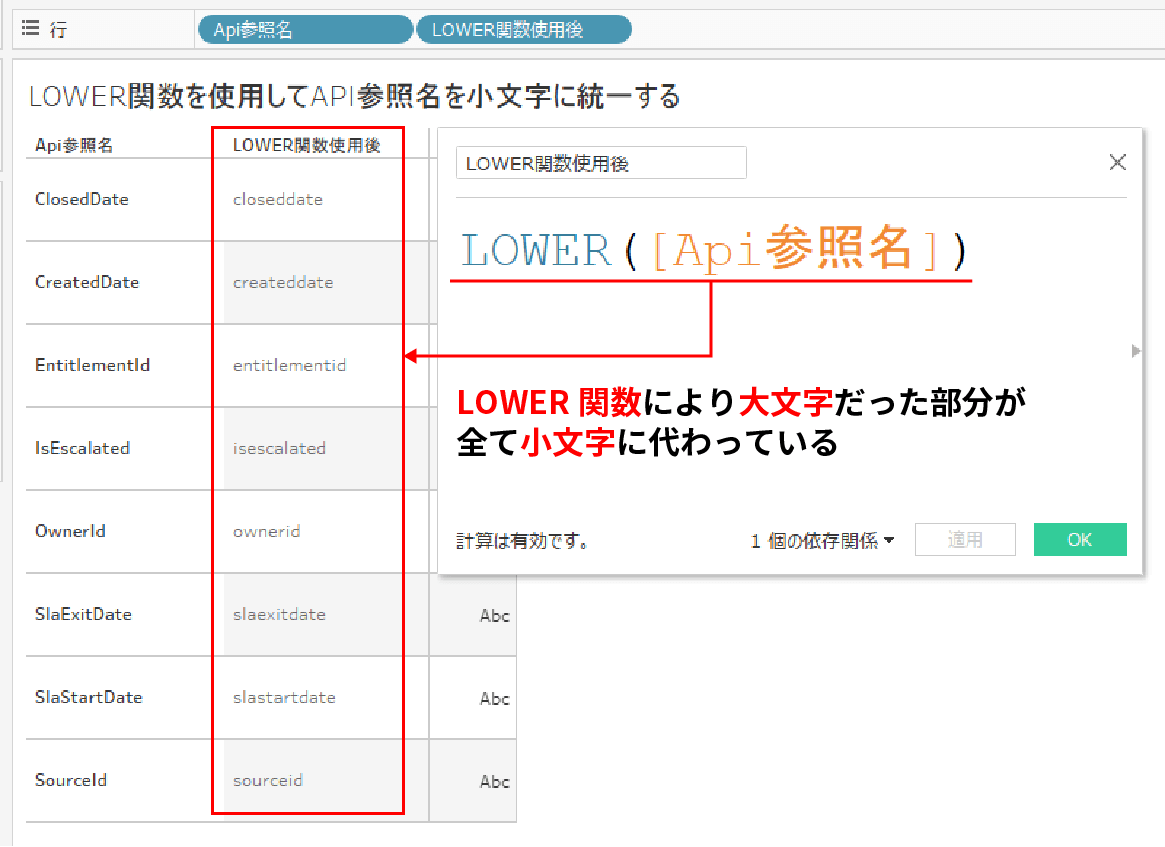
LOWER関数によって大文字部分が小文字になっていることがお分かりいただけると思う。
このようにLOWER関数は大文字と小文字が混じっている値や大文字のみの値を全て小文字に変換してくれる。
ただし、注意点としては小文字に変換できるのはアルファベットのみだ。
漢字や数字に対してLOWER関数を使用しても意味がないのは覚えておこう。
LOWER関数の使い方
LOWER関数の使い方はシンプルで大文字から小文字に変換したいフィールドを下記のように指定するだけだ。
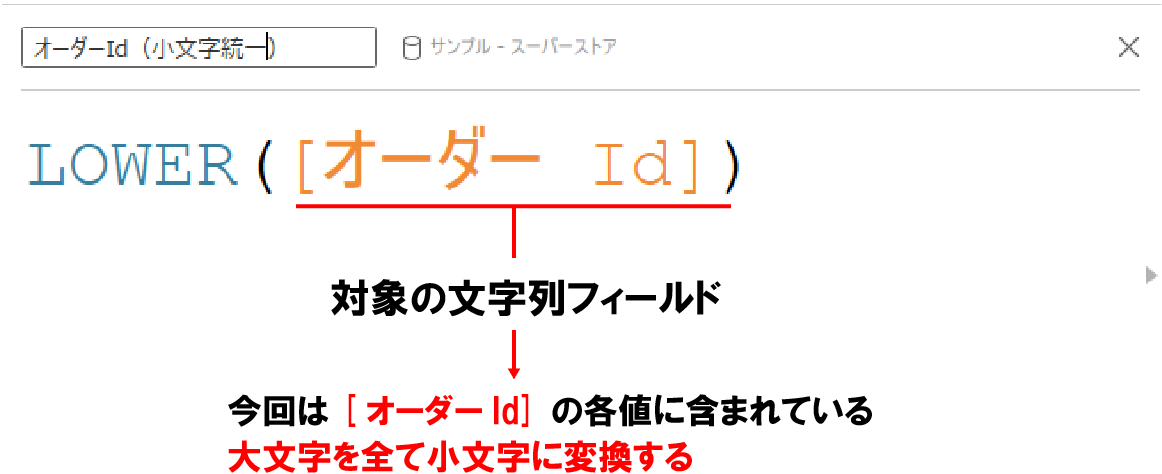
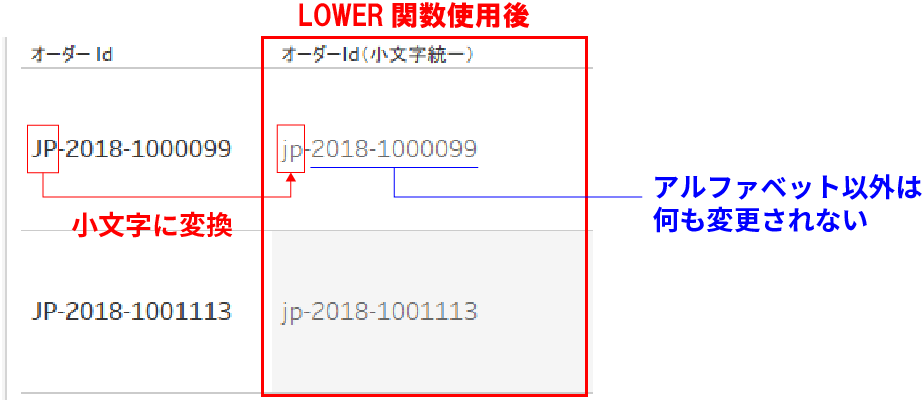
上記のように指定した結果が下記で、アルファベットの大文字のみが小文字になっていることがお分かりいただけると思う。
LOWER関数の詳細は下記記事にまとめているので、詳しく知りたい方は参考にして欲しい。
【Tableau】LOWER関数とは? 意味から使い方までわかりやすく解説
RIGHT関数
RIGHT関数は対象の文字列の一番右から指定した文字数までの文字を返してくれる関数だ。
前述したLEFT関数は左だったが、RIGHT関数はその名の通り、右から指定した文字を取得してくれる。
例えば、下記はRIGHT関数を使用して、会員番号を右から6桁を取得した例だ。
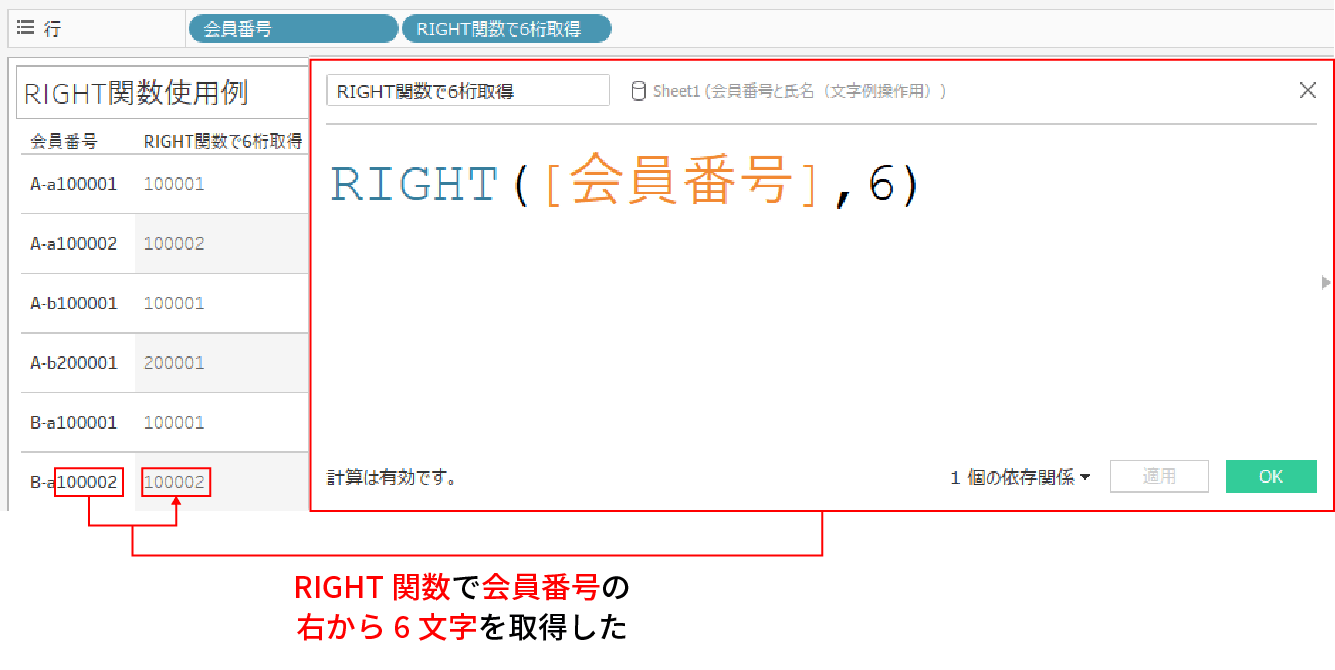
右から6文字が取得できていることがお分かりいただけると思う。
RIGHT関数の使い方
RIGHT関数の使い方は下記の通りだ。
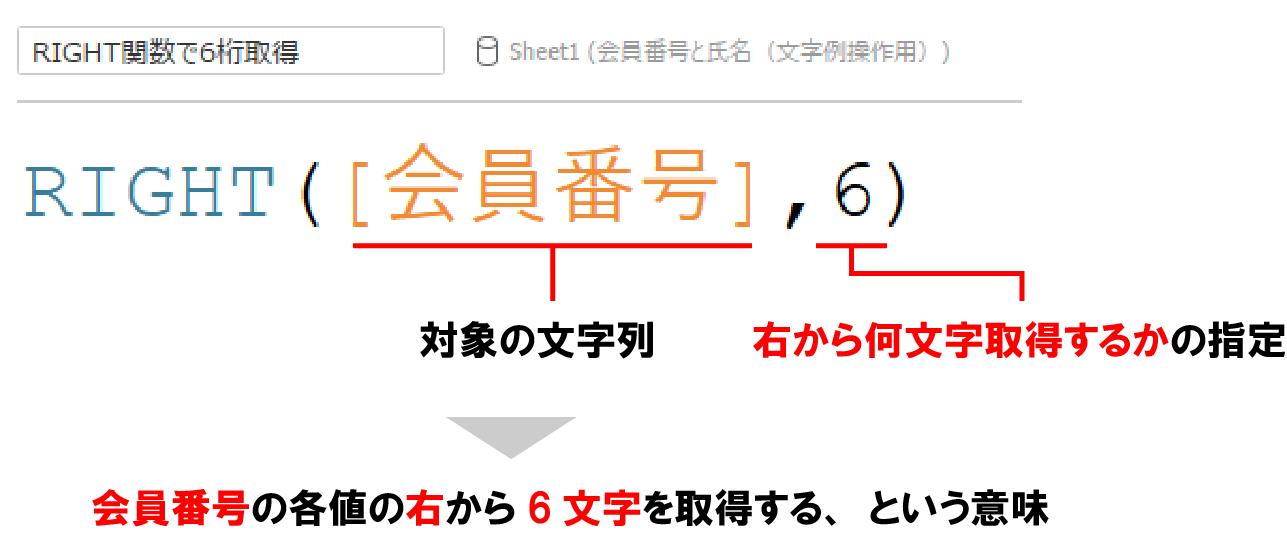
個人的にはLEFT関数に比べてRIGHT関数を使う機会は多くない。
だが、「右から~文字分を取得したい」という場合にサクッと使うことが出来るので覚えておくと役に立つ場合が出てくるはずだ。
STARTSWITH関数
STARTSWITH関数は対象の文字列が指定した文字列で始まるかを判定してTRUEもしくはFALSEを返してくれる関数だ。
前述したENDSWITH関数の反対だ。
例えば、下記はSTARTSWITH関数で会員番号の先頭文字が A かどうかを判定している例だ。
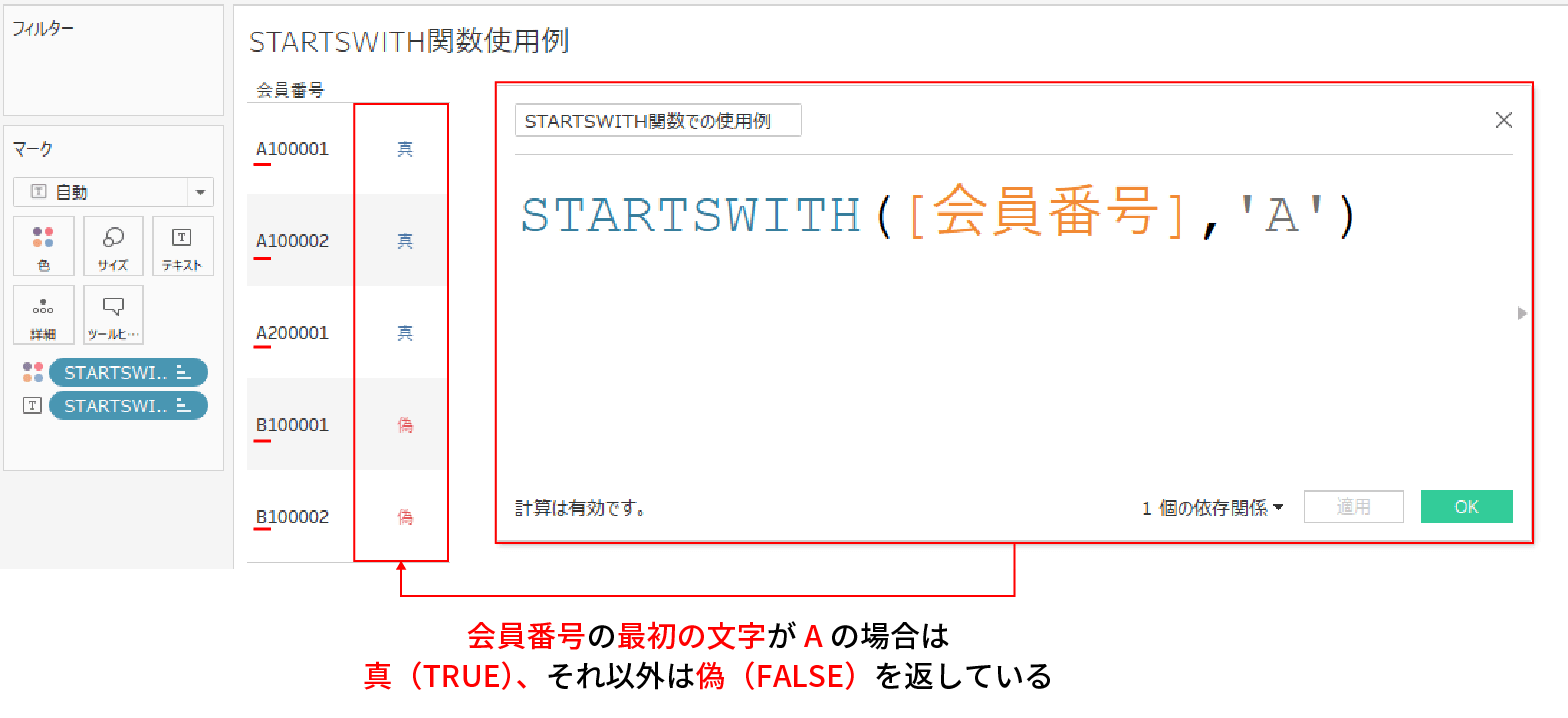
ENDSWITH関数と異なり、STARTSWITH関数は対象の文字列がどの文字列で始まるかを判定していることがお分かりいただけると思う。
STARTSWITH関数の使い方
STARTSWITH関数の使い方は下記の通りだ。
下図では判定したい先頭文字と記載があるが、1文字ではなく、例えば、ABS等の数文字での指定も可能だ。
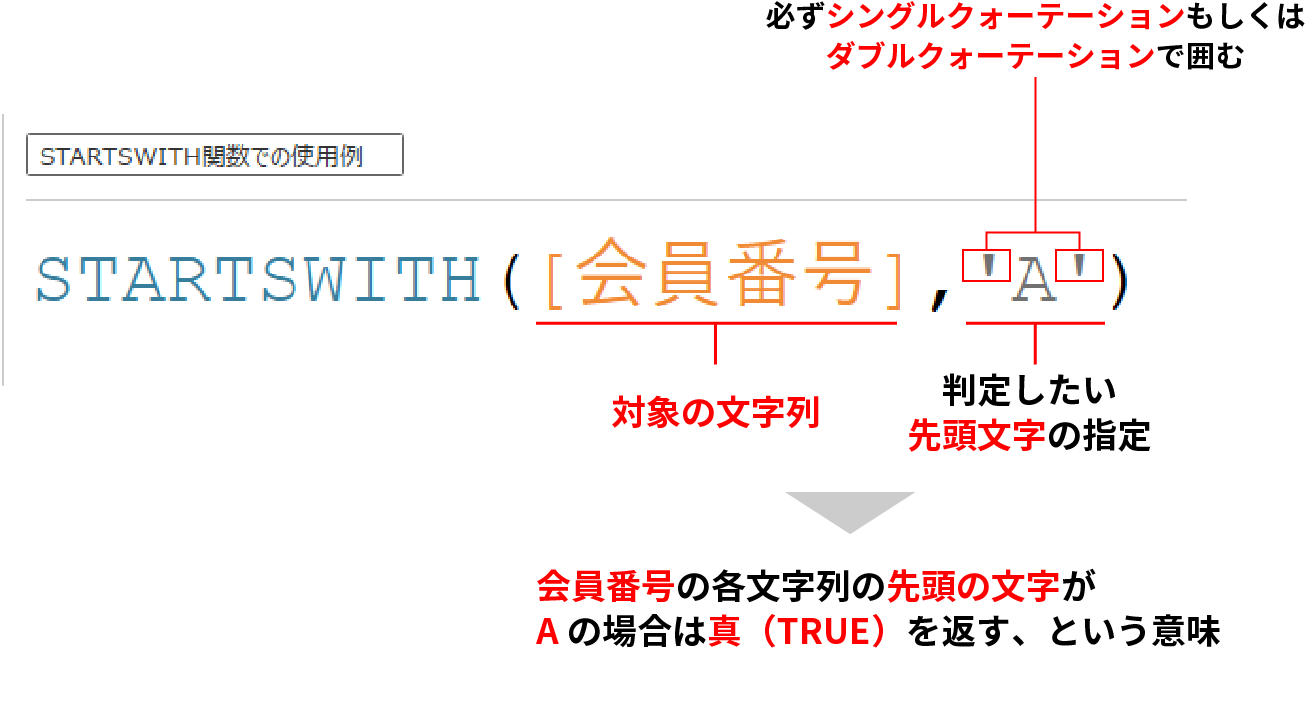
必ず判定したい文字列を指定する際にシングルクォーテーションもしくはダブルクォーテーションで囲むことは忘れないようにしたい。
データベースによっては、会員IDの先頭3文字が顧客カテゴリ等を表している、という場合があったりする。
そういう時にIF文とSTARTSWITH関数を組み合わせて
「先頭から3文字が~の場合はAカテゴリ、~の場合はBカテゴリ」
とどの文字列から始まるかによって場合分けをし、グルーピングをするという活用方法が考えられる。
UPPER関数
UPPER関数は対象の文字列の全ての文字を大文字に変換してくれる関数だ。
前述したLOWER関数の真逆の関数となる。
例えば、下記ではUPPER関数を使用して、「Api参照名」というカラムの各値の小文字を大文字に変換している。
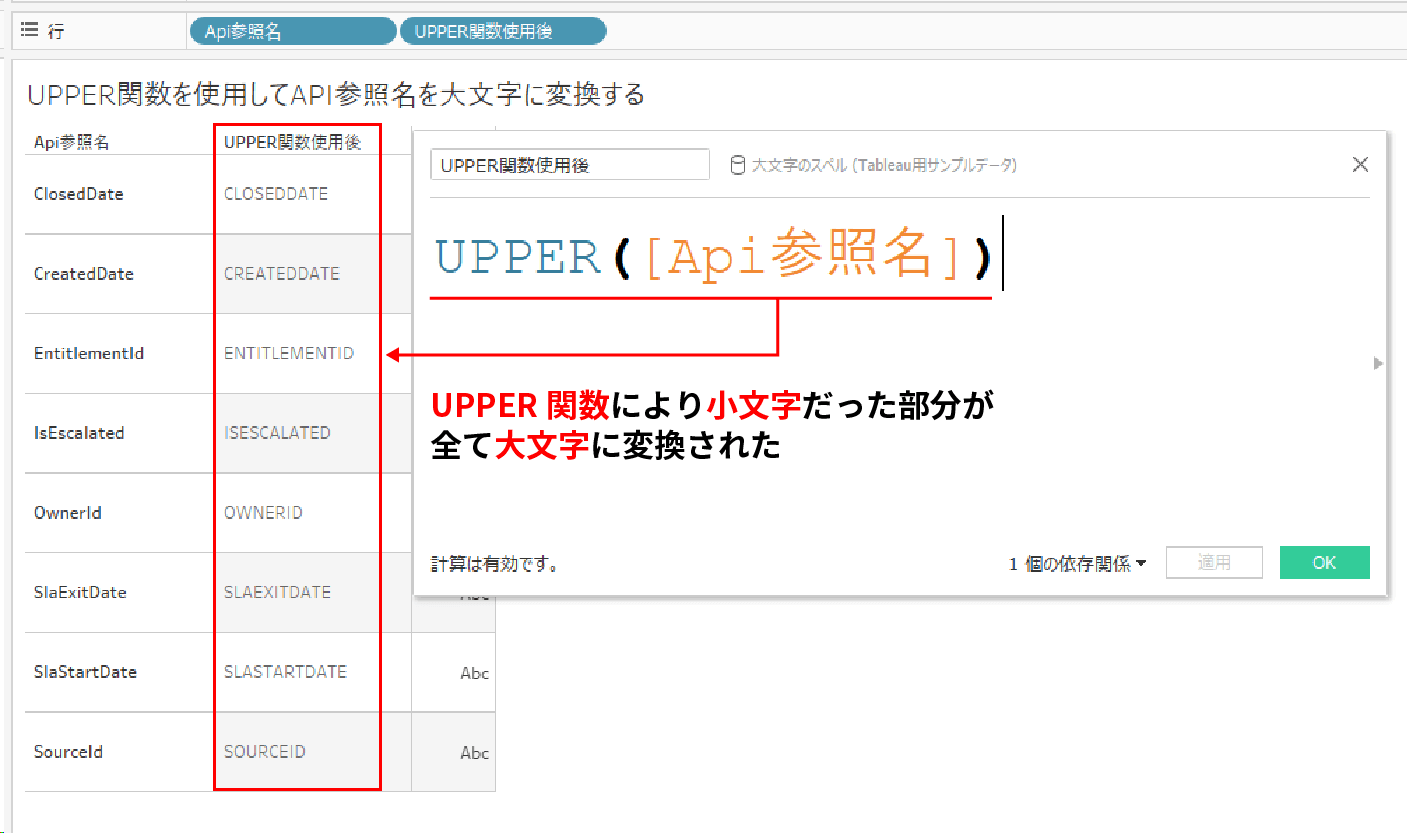
アルファベットの小文字が全て大文字に変換されていることがお分かりいただけると思う。
機能としてはLOWER関数と真逆だが、大文字に変換できるのはアルファベットのみという点は共通している。
UPPER関数の使い方
UPPER関数の使い方はLOWER関数と同様に非常にシンプルだ。
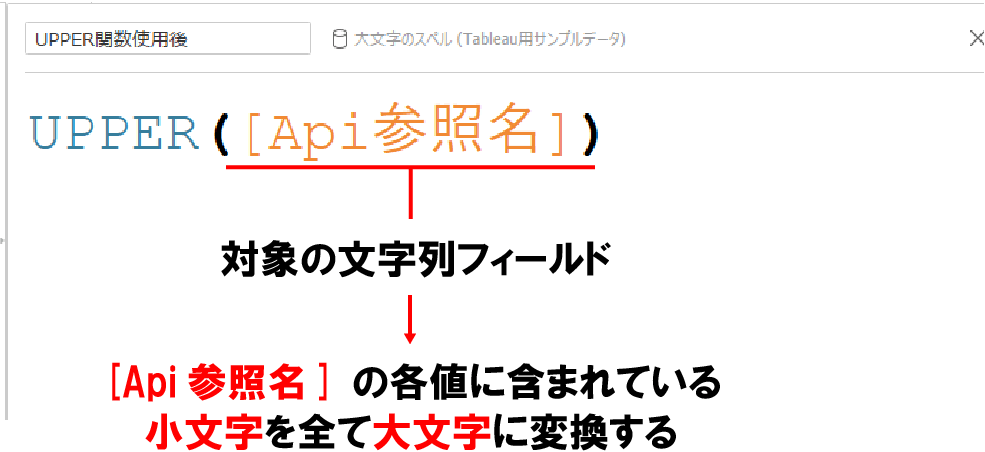
上記のように対象の文字列フィールドをUPPER()内に指定するだけで使うことが出来る。