
今回はBigQueryの数値を表すデータ型(数値型)について整理する。
数値型は名前の通り、数値を保存出来るデータ型だ。
BigQueryにおいて数値型は4種類あり、それぞれに特徴があるが、それぞれの違いや「テーブル定義の際にどの型を使うべきか?」は混乱しがちだ。
そこで今回は私の備忘録も含めて、数値を表すデータ型の違いや使い分けについて整理していこうと思う。
目次
数値を表すデータ型一覧
BigQueryにおける数値を表すデータ型は下記4種類だ。
- INT64(INTEGER)
- FLOAT64(FLOAT)
- NUMERIC
- BIGNUMERIC
その内、赤字の3つのデータ型はよく使うので、しっかり違いを整理しておいてほしい。
それぞれの特徴と使用例、1つの値を格納する際に必要なストレージサイズは下図の通りだ。
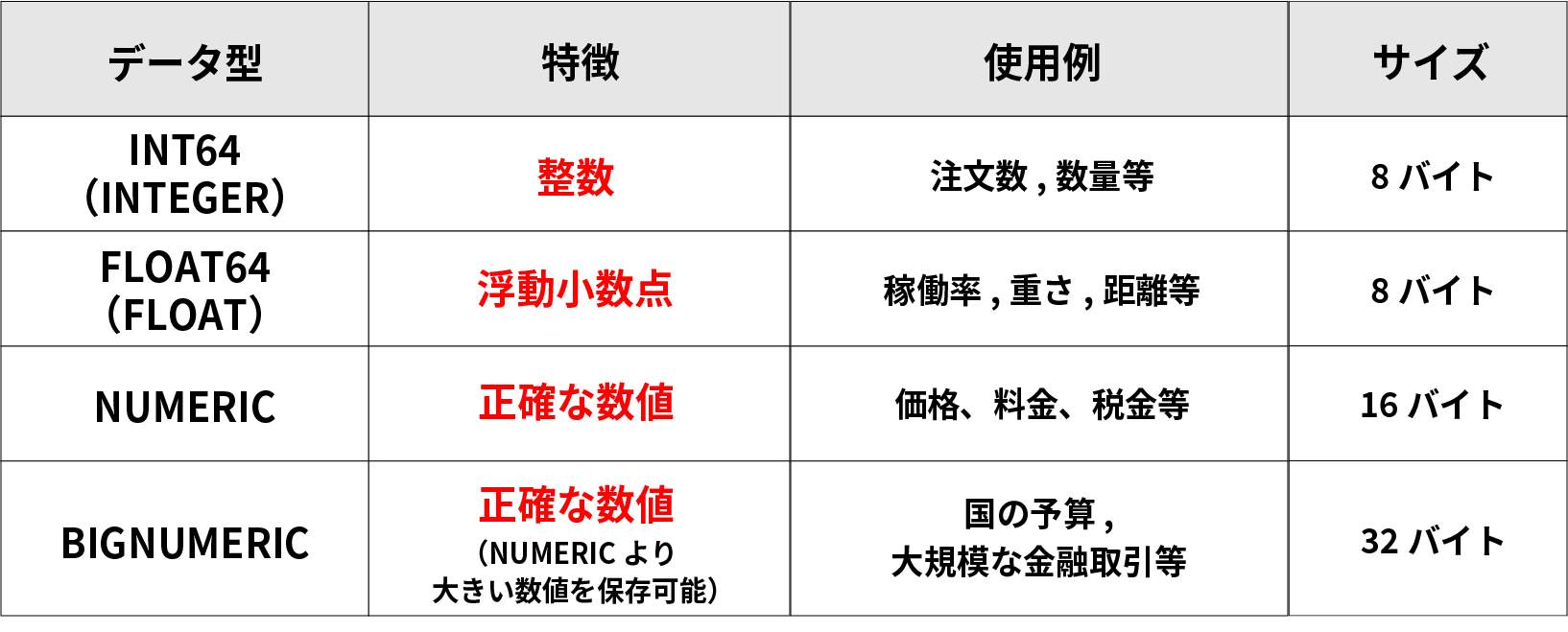
上図の通り、それぞれのデータ型によって特徴や適している使用シーンが異なる。
1つずつ具体的に見ていこう。
INT64
INT64型(INTEGER)は整数を格納することが出来るデータ型だ。
INT64型で扱える整数の範囲は下記となる。
- -9,223,372,036,854,775,808~9,223,372,036,854,775,807
かなり大きな数値まで扱えることがお分かりいただけると思う。
ただ、INT64は整数のみを扱うことができるので、小数点が含まれているデータは扱うことが出来ない。
そのため、使用シーンとしては注文数や数量、ランクなど小数点が発生しない数値を扱うデータ等に適している。
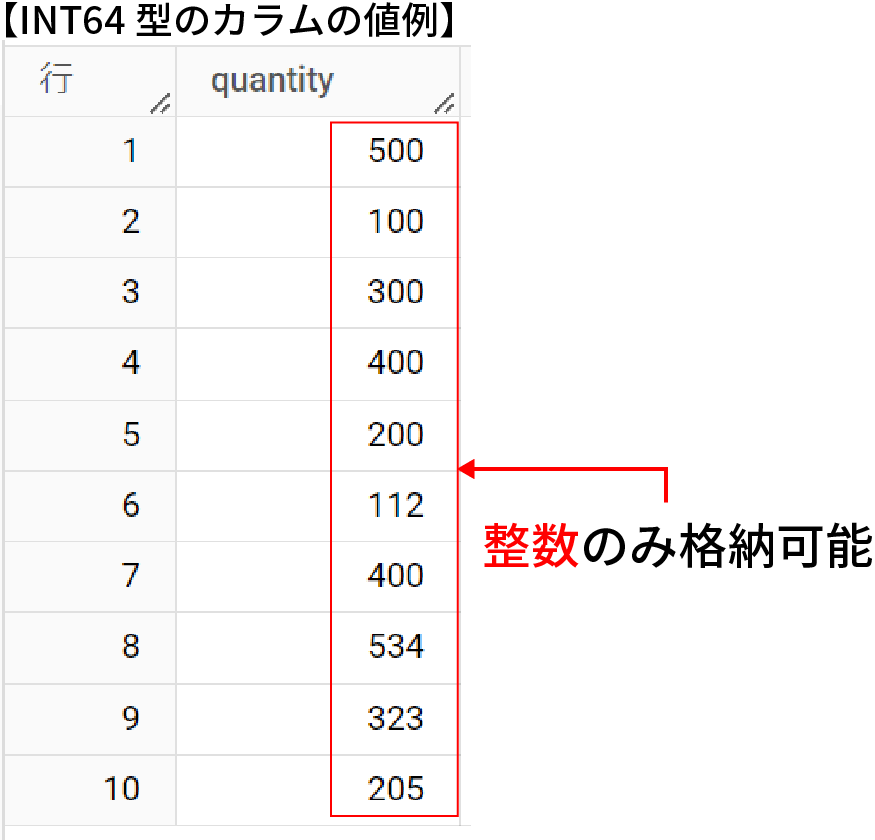
実際にINT64型を指定してquantityカラムを作成したクエリと作成されたテーブル(int64_table)が下記となる。
1 2 3 | CREATE TABLE `sample.sampledataset.int64_table` ( quantity INT64 ); |
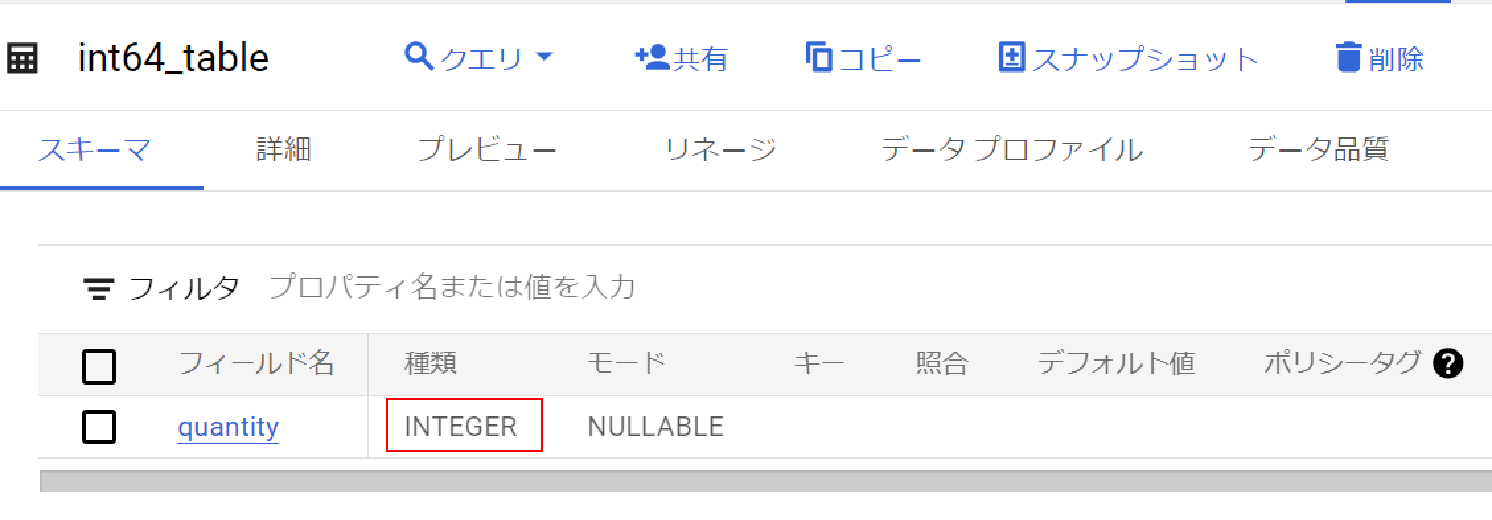
テーブル作成時に「INT64」と指定して作成したが、BigQuery上のquantityの表記は「INTEGER」と表記されている。
このように、BigQueryのWeb UI(コンソール)では、このINT64型が単純にINTEGERとして表示されることがある。
INT64の64ってどういう意味?
「INT64の64ってどういう意味なんだろう?」
と疑問に思っていたが、64ビット、すなわち64の2進数の桁を使用して整数を表現することを意味している。
ちなみに64ビットは8バイトに相当する。
そのため、INT64型のカラムで1つの値を格納する際は8バイトのストレージを使用するのだ。
FLOAT64
FLOAT64(FLOAT)は倍精度浮動小数点数の近似値を格納することが出来るデータ型だ。
倍精度浮動小数点数がわかりにくく、
「???」
となる人も多いと思うが、64ビット(=8バイト)のデータ型で、一定の精度で広範囲の小数点を含む数値を表現できるものだ。
例えば、3.14や1.23などの小数点を含む値を格納出来るのがFLOAT64となる。
使用シーンとしては気温や湿度、距離や重さ、工場のセンサー等のデータを格納する際だ。
小数点を含むがそこまで絶対的な精度が必要ないデータに適している。
INT64型のカラム同士の比を算出したり、稼働率などの割合を出す時にもよく使われる。
FLOAT64の注意点
このように便利なFLOAT64だが、わずかな誤差が生じる可能性がある点は要注意だ。
FLOAT64は小数部分の近似小数値を2進数で表すため、絶対的な正確性が必要な財務データなどお金を扱う時は使うのを避けた方が良い。
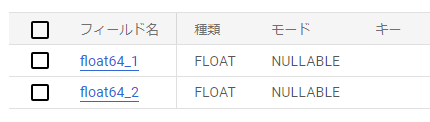
例えば、下記のような下記2つのカラムがあるテーブルがあるとする。
| float64_1 | float64_2 |
| 0.1 | 0.2 |
どちらも下記のようにFLOAT64型だ(INT64と同じく単純にFLOATと表示されている)
このデータを下記クエリで2つのカラムを足し合わせたfloat64_3を作成してみる。
1 2 3 4 5 6 | SELECT float64_1 ,float64_2 ,float64_1+float64_2 AS float64_3 FROM `sample_float64` |
そうすると、本来は0.1+0.2=0.3の結果になるはずなのに、下記のようにほんのわずかな誤差が生じるのだ。

このようにFLOAT64はあくまで2進数で小数点の近似値を表しているため、このような誤差が生じる場合があるのだ。
1つ1つの誤差がほんのわずかでもお金に関係するデータでFLOAT64を使用してしまうと
「1円ずれているが原因がわからない、、、」
というような問題が発生する。
そのため、お金に関係するデータに関しては次のNUMERICを使うことをおすすめする。
ただし、速度やストレージサイズを考えるとFLOAT64は便利だ。
そのため、厳密な精度が求められない小数点が含まれるデータ(重さや距離、気温など)はFLOAT64の利用を検討しよう。
NUMERIC
NUMERIC 型は、小数点を含む数値を格納できる正確な数値データ型だ。
NUMERIC型は10進数の38桁(小数は最大9桁まで)までの値に関して、FLOATのように誤差が生じることがない正確な数値を表すことが出来る。
そのため、絶対的に正しい数値が必要な場合や財務データなどのお金に関係するデータを扱う際は NUMERIC 型が適している。
NUMERICでは誤差が生じない
NUMERICはFLOAT64と違い、10進数38桁の範囲内の値において絶対的に正しい数値を表すことが出来る。
例えば、FLOAT64で先ほど誤差が出た足し算をNUMERIC型に置き換えて実施してみたクエリと結果が下記だ。
1 2 3 4 5 6 | SELECT numeric_1 ,numeric_2 ,numeric_1+numeric_2 AS numeric_3 FROM `sample_numeric` |
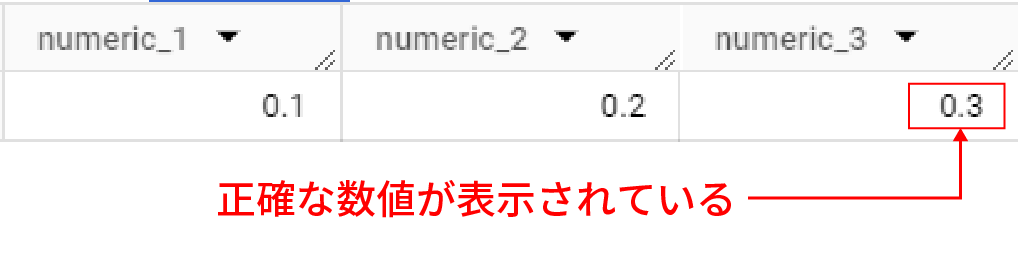
このようにFLOAT64では生じていた誤差がNUMERICの場合は正確な数値で表すことができる。
そのため、財務データなどのお金に関係するデータはNUMERICが適しているのだ。
ただし、精度が保証される分、1つの値を格納する時に必要なストレージサイズはFLOAT64が8バイトに対して、NUMERICは16バイトと2倍になる。
また、データ量によるがクエリの実行時間もFLOAT64に比べるとやや遅くなる点は留意しておく必要がある。
BIGNUMERIC
BIGNUMERIC型はNUMERIC型よりも大きな数値を格納できるデータ型だ。
具体的には最大で76桁の数字を保持することができ(38桁の整数部と38桁の小数部)、小数点以下の精度も38桁までサポートしている。
扱うことが出来る範囲が大きい分、BIGNUMERICでは1つの値を格納するために必要なストレージサイズは32バイトとなる。
つまり、INT64やFLOAT64の8バイトの4倍、NUMERICの16バイトに比べて2倍の大きさが必要ということだ。。
BIGNUMERIC型はNUMERIC型の最大値では扱えないような大きな数値を正確に表したい場合に利用することが考えられる。
例えば、国の予算や大規模な金融取引などの桁違いに大きな数値を扱う際に使用されると思うが、実際に使用する人は少ないかもしれない。
まとめ
今回はBigQueryにおける数値型の種類とその違いを整理してみた。
- BigQueryで使える数値型データ型は4種類:
INT64、FLOAT64、NUMERIC、BIGNUMERIC - 精度・パフォーマンス・ストレージのトレードオフに注意し、用途に応じて適切な型を選ぶことが重要
- 浮動小数点(FLOAT64)では
0.1 + 0.2 ≠ 0.3のような誤差が発生することがあるので注意 - お金に関わるデータにはFLOATではなくNUMERICまたはBIGNUMERICを使うべき
改めて下図でそれぞれの違いを整理してみて欲しい。
BigQueryにおける日時を表すデータ型の種類については下記記事で詳しく解説している。





